OpenGL 学习笔记(二)
坐标变换
在介绍完 OpenGL 的概念和 Mac 下环境设置以后,接下来我们先从整体上介绍一下 OpenGL 的渲染流程。我们知道,OpenGL 中的任何物体都是使用三维坐标表示的,而经过渲染之后最终显示在我们眼前的却是屏幕中的二维坐标物体。因此,渲染流程其实就是从三维坐标转换到二维屏幕像素的过程。尽管这个定义看起来很简单,但是却包含了两个复杂的流程:空间坐标变换和像素渲染。本文介绍第一个过程,也就是空间坐标变换。
在介绍完 OpenGL 的概念和 Mac 下环境设置以后,接下来我们先从整体上介绍一下 OpenGL 的渲染流程。我们知道,OpenGL 中的任何物体都是使用三维坐标表示的,而经过渲染之后最终显示在我们眼前的却是屏幕中的二维坐标物体。因此,渲染流程其实就是从三维坐标转换到二维屏幕像素的过程。尽管这个定义看起来很简单,但是却包含了两个复杂的流程:空间坐标变换和像素渲染。本文介绍第一个过程,也就是空间坐标变换。
作为一个经验丰富的程序员,有哪些事情是你希望在一开始编程的时候就知道的?或者换个方式来说,你认为每个新手程序员应该做或者学什么才能让自己的编程水平更好?
下面是一位 CTO Ken Mazaika 的观点,很有分享价值:
有经验的程序员会做到下面 29 项事情,这也是每个新手程序员应该知道的事情。如果你想成为更好的开发者,你应该尤其注意第 15 点和第 29 点。
这篇文章为 Python 编程者提供了一个使用 protobuf 的基本教程。下文通过创建一个简单的应用,向你展示了三点主要内容:
.proto 文件中定义消息(Message)格式这并不是一个在 Python 中使用 protobuf 的完整的教程。如果你需要更加详细的信息,可以查看 Protocol Buffer Language Guide,Python API Reference,Python Generated Code Guide 以及 Encoding Reference。
我们接下来将使用一个非常简单的『地址簿』应用,该应用将能够从一个文件中读取某人的联系方式或将联系方式写回到文件中。在地址簿中的每个人都有一个姓名,ID,email 以及联系电话。
作为一个游戏开发者,如果不懂图形学渲染,那么你会很悲剧
在开始整个学习之前,我们需要知道 OpenGL 是什么。根据 wikipedia 的定义:
OpenGL 是用于渲染 2D、3D 矢量图形的跨语言、跨平台的应用程序编程接口(API)。这个接口由近 350 个不同的函数调用组成,用来从简单的图形比特绘制复杂的三维景象。
这个定义告诉我们 OpenGL 本身即不是编程语言,也不是程序库,而是一个 API 标准。事实上,OpenGL 的 API 仅仅定义了若干可被客户端程序调用的函数,以及一些具名整型常数(例如,常数 GL_TEXTURE_2D 对应的十进制整数为 3553 )。虽然这些函数的定义表面上类似于 C 语言,但它们是语言独立的。因此,OpenGL 有许多语言绑定,值得一提的包括:JavaScript 绑定的 WebGL(基于 OpenGL ES 2.0 在 Web 浏览器中的进行 3D 渲染的 API);C 绑定的 WGL、GLX 和 CGL;iOS 提供的 C 绑定;Android 提供的 Java 和 C 绑定等。
更近一步讲,OpenGL 不仅语言无关,而且平台无关。其规范只字未提获得和管理 OpenGL 上下文相关的内容,而是将这些作为细节交给底层的窗口系统。出于同样的原因,OpenGL 纯粹专注于渲染,而不提供输入、音频以及窗口相关的 API。
在本文中以及后文中,我们关注的 OpenGL 实现方案均限定于 C++ 语言。
Python 中的方法解析顺序(Method Resolution Order, MRO)定义了多继承存在时 Python 解释器查找函数解析的正确方式。当 Python 版本从 2.2 发展到 2.3 再到现在的 Python 3,MRO算法也随之发生了相应的变化。这种变化在很多时候影响了我们使用不同版本 Python 编程的过程。
MRO 全称方法解析顺序(Method Resolution Order)。它定义了 Python 中多继承存在的情况下,解释器查找函数解析的具体顺序。什么是函数解析顺序?我们首先用一个简单的例子来说明。请仔细看下面代码:
class A():
def who_am_i(self):
print("I am A")
class B(A):
pass
class C(A):
def who_am_i(self):
print("I am C")
class D(B,C):
pass
d = D()
如果我问在 Python 2 中使用 D 的实例调用 d.who_am_i(),究竟执行的是 A 中的 who_am_i() 还是 C 中的 who_am_i(),我想百分之九十以上的人都会不假思索地回答:肯定是 C 中的 who_am_i(),因为 C 是 D 的直接父类。然而,如果你把代码用 Python 2 运行一下就可以看到 d.who_am_i() 打印的是 I am A。
是不是觉得很混乱很奇怪?感到奇怪就对了!!!
程序设计语言是向人和计算机描述计算过程的记号。如我们所知,这个世界依赖于程序设计语言,因为在所有计算机上运行的所有软件都是用某种程序设计语言所编写。但是,在一个程序可以运行之前,它首先需要被翻译成一种能够被计算机识别的形式。
完成这项翻译工作的软件系统被称为编译器。
尽管在任何一门有关编译原理的课程上都会提到编译和解释的概念,但是不是每个人都能清楚地说明这两者之间的区别。下图从用户的角度给出了编译器和解释器处理用户程序的基本过程。
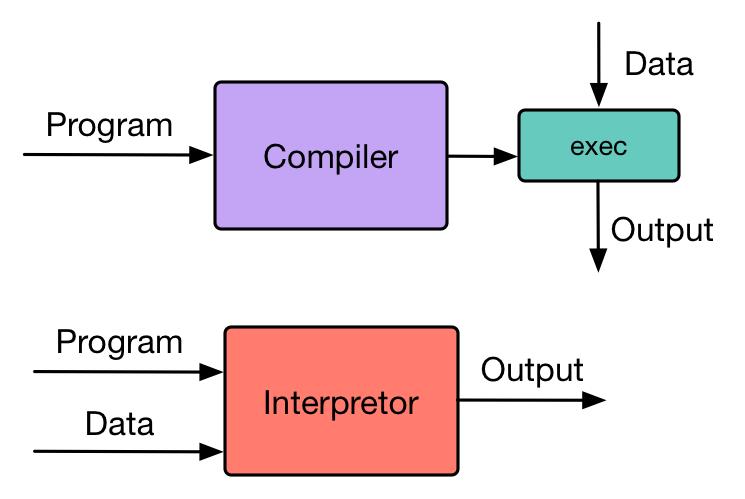 图1:Compiler vs Interpretor
图1:Compiler vs Interpretor
按照上面的定义,我们通常所用的 Python 是一种解释性语言,但事实上 Python 兼具了编译和解释的过程。一个 Python 程序首先被编译成为 Python 字节码,然后通过 Python 虚拟机解释执行。
