回顾一下在第一篇关于leveldb的目录中所介绍的内容,leveldb 最重要结构之一即是存储在内存中的 Memtable 和 Immutable Memtable。leveldb 每次在写入一个 Key/Value 对时,首先将该操作追加到 log 中,然后再将其写入到内存的 Memtable 中。如果 Memtable 的内存占用超过指定值,则 Leveldb 就自动将其转换为 Immutable Memtable,并自动生成新的 Memtable。Immutable Memtable 会被后台线程转储到磁盘中,构成磁盘上的 SSTable 结构。
MemTable 结构定义在文件 memtable.h 中,其成员变量如下:
class MemTable {
private:
typedef SkipList<const char*, KeyComparator> Table;
Table table_;
Arena arena_;
KeyComparator comparator_;
int refs_;
...
}
leveldb 中的 MemTable 基于跳表 SkipList 来实现对于键值对的有序管理,通过内存管理器 Arena 来为插入的 key/value 对申请内存,并通过记录引用数量 refs_ 来决定内存释放。
Memtable 中的 key
在分析 memtable 如何组织键值对之前,有必要先介绍一下 Memtable 是如何保存和管理键结构的。Leveldb 中有三个关于 key 的概念:
- UserKey:用户提供的键值
- InternalKey:UserKey + SequenceNumber
- LookupKey:EncodeString(InternalKey.size()) + InternalKey
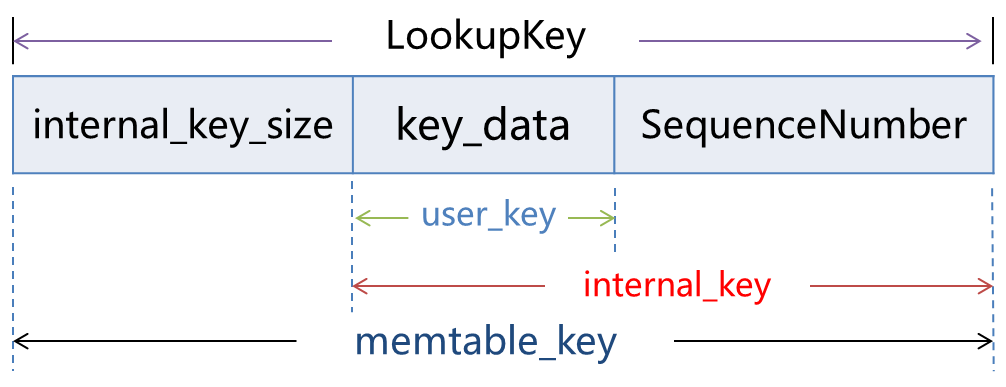
上图给出了这三种 key 之间的关系,UserKey 是用户调用接口 DB::Put(key, value) 是插入的键值。当用户插入键值时,memtable 中的接口 Add 将会在 UserKey 的后面拼接上一个 64-bit 的 SequenceNumber 从而得到 InternalKey。这个 64-bit 的 SequenceNumber 中高 56-bit 是用来真实存放当前操作的序列号(全局递增,用来进行版本管理);后 8-bit 存放了该键值的类型 ValueType:
enum ValueType {
kTypeDeletion = 0x0,
kTypeValue = 0x1
};
在 memtable 中插入键值对时,该键值的类型被设置成为 kTypeValue;而当删除某个键值对,memtable 不会立即将其从表中删掉,而是将其插入到表中,并且将其类型设置成为 kTypeDeletion。因此 InternalKey 顾名思义就是经过包装的供内部使用的 key。
Memtable 的查询接口 Get 传入的是结构 LookupKey,或者称为 Memtable key。这个结构首先将 InternalKey 的长度通过变长字符串进行编码,然后再拼接 InternalKey 形成。可以理解成为带有长度编码的 InternalKey。
memtable 定义了这几种 key 相互转化以及打包的接口,定义在文件 db_format.cc 中。当了解了格式,再去理解实现应该比较容易。
跳表 SkipList
跳表 SkipList 是 构成 Memtable 最基本的结构。跳表的提出者 William Pugh 在 1989 的论文中指出:
Skip lists are a probabilistic data structure that seem likely to supplant balanced trees as the implementation method of choice for many applications. Skip list algorithms have the same asymptotic expected time bounds as balanced trees and are simpler, faster and use less space.
跳表具有与平衡树相同的渐进复杂度,并且其实现更加简单,运行更快并占用更少的空间。不同于 redis 为跳表节点增加了回溯指针,span 成员等,leveldb 中使用了经典的跳表结构。关于跳表的定义和分析,这里不再赘述,仅用下图来辅助理解:
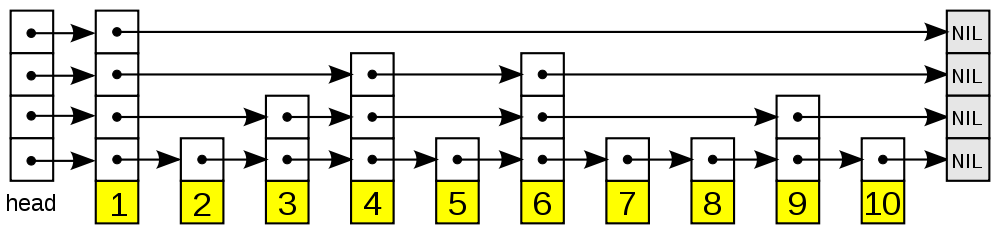
leveldb 中的跳表实现非常简洁。跳表的节点 Node 被定义为柔性数组:
template<typename Key, class Comparator>
struct SkipList<Key,Comparator>::Node {
private:
port::AtomicPointer next_[1]; // flexible array
}
同时作者为跳表本身定义了迭代器 Iterator。事实上,迭代器的设计模式可以说是 leveldb 的一大特点,作者大量使用迭代器来封装细节,提供抽象,从而提供优雅的遍历,查找等功能实现。跳表的迭代器本身非常好理解,函数的定义也是 self-explanation。
作者在跳表中定义了几个非常方便的私有函数来辅助实现迭代器以及跳表的对外接口:
//判断 Key 是否大于节点 Node 中存储的 Key 值
bool KeyIsAfterNode(const Key& key, Node* n) const;
// 寻找第一个大于等于 Key 值的节点,同时将该节点的前置节点存放在数组 prev 中
Node* FindGreaterOrEqual(const Key& key, Node** prev) const;
// 寻找第一个键值小于 key 的节点
Node* FindLessThan(const Key& key) const;
我们以 FindGreaterOrEqual 为例来分析这几个辅助函数的实现:
template<typename Key, class Comparator>
typename SkipList<Key,Comparator>::Node*
SkipList<Key,Comparator>::FindGreaterOrEqual(const Key& key, Node** prev)
const {
Node* x = head_;
int level = GetMaxHeight() - 1; //获得跳表的最高层
while (true) {
Node* next = x->Next(level); // 从最高层还是查找
if (KeyIsAfterNode(key, next)) { // 如果当前的节点键值较小,向后移动
x = next;
} else {
if (prev != NULL) prev[level] = x;
if (level == 0) {
return next;
} else {
level--; // 下降一层继续查找
}
}
}
}
可以看到该函数的实现条理非常清晰,主要分为如下几步:
- 从跳表的最高层链表开始查找,如果当前的节点小于键值 key,那么指针向后移动;
- 如果当前节点大于等于键值 key,首先记录该节点的前置节点,然后判断当前所在的层数;
- 如果当前已经抵达最底层,那么直接返回找到的节点,否则降低一层继续查找。
利用这几个辅助函数,可以较为容易地实现跳表的插入,查找等操作,这里的分析以 Insert 函数为例:
template<typename Key, class Comparator>
void SkipList<Key,Comparator>::Insert(const Key& key) {
Node* prev[kMaxHeight];
// 寻找到插入位置,prev 数组会被填充为该节点在不同层次上的前置节点
Node* x = FindGreaterOrEqual(key, prev);
// 不允许出现相同的键值
assert(x == NULL || !Equal(key, x->key));
int height = RandomHeight(); // 随机计算该节点的高度
if (height > GetMaxHeight()) {
for (int i = GetMaxHeight(); i < height; i++) {
prev[i] = head_; // 设置该节点在新层数上的前置节点为表头
}
max_height_.NoBarrier_Store(reinterpret_cast<void*>(height));
}
x = NewNode(key, height);
for (int i = 0; i < height; i++) { // 将该节点串接到所有的链表中
x->NoBarrier_SetNext(i, prev[i]->NoBarrier_Next(i));
prev[i]->SetNext(i, x);
}
}
结合代码和注释应该已经很容易理解,无需赘述。
Memtable 的实现
Memtable 提供了如下几个接口:
void Add(SequenceNumber seq, ValueType type, const Slice& key,
const Slice& value);
bool Get(const LookupKey& key, std::string* value, Status* s);
size_t ApproximateMemoryUsage();
Iterator* NewIterator();
void Ref();
void Unref();
其中 Add 和 Get 很好理解,用来添加和获取一个键值对的值,注意 Memtable 是没有删除的,删除操作通过插入一个 kTypeDeletion 的 key 来实现。函数 ApproximateMemoryUsage 返回该 Memtable 的非精确的内存使用量;NewIterator 返回 Memtable 的迭代器,用来进行顺序访问以及 seek 操作。
Memtable 本身基于引用计数来管理,当外部使用到该 Memtable 时,其引用计数加一;当没有外部使用者时,该 Memtable 占用的内存将全部被释放。因此对于 Memtable 而言,没有单独释放某个 key/value 内存空间的概念。这也就是为什么 Arena 除了析构函数以外不提供任何内存释放操作的原因。
结合我们上面给出的 key 结构图,可以很容易理解 Add 函数:
void MemTable::Add(SequenceNumber s, ValueType type,
const Slice& key,
const Slice& value) {
size_t key_size = key.size(); // user_key
size_t val_size = value.size();
size_t internal_key_size = key_size + 8; // 计算 InternalKey长度
const size_t encoded_len =
VarintLength(internal_key_size) + internal_key_size +
VarintLength(val_size) + val_size;
char* buf = arena_.Allocate(encoded_len); // 申请内存
char* p = EncodeVarint32(buf, internal_key_size); // 将InternalKey长度编码
memcpy(p, key.data(), key_size);
p += key_size;
EncodeFixed64(p, (s << 8) | type); // 填充SequenceNumber 和 Type
p += 8;
p = EncodeVarint32(p, val_size); // 将 value 长度进行编码
memcpy(p, value.data(), val_size); // 保存 value 值
assert((p + val_size) - buf == encoded_len);
table_.Insert(buf); // 插入到跳表中
}
接下来我们再看一下根据 LookupKey 获取值的接口 Get。这个函数首先由 LookupKey 返回 memtable_key 字符串(这两个不同结构表示的字符串内容是一致的),初始化迭代器 Iterator 并调用 Seek,直接定位到第一个大于或等于 memtable_key 的条目:
Slice memkey = key.memtable_key();
Table::Iterator iter(&table_);
iter.Seek(memkey.data());
然后对该条目进行解析,将 InternalKey 的长度解析到参数 key_length 中,然后取出该条目对应的 user_key 并调用 user_comparator() 来比较其是否与传递的参数 key 相等:
const char* entry = iter.key(); // 当前条目对应的 LookupKey
uint32_t key_length;
// 解析 InternalKey 的长度到 key_length
const char* key_ptr = GetVarint32Ptr(entry, entry+5, &key_length);
// 比较当前条目对应的 user_key 与 参数 key 是否相等
if (comparator_.comparator.user_comparator()->Compare(
Slice(key_ptr, key_length - 8),
key.user_key()) == 0) {
...
}
如果相等,表示找到了 key 所对应的条目,则将 InternalKey 中保存的 TypeValue 取出来进行判断。如果当前条目类型是 kTypeValue,表示其确实存在于 Memtable 中,可以将其保存的 value 值解析出来并返回;如果对应的类型是 kTypeDeletion,表示该 key/value 已经从 Memtable 中删除,这时候将 NotFound 保存在状态码中,并且返回。
const uint64_t tag = DecodeFixed64(key_ptr + key_length - 8);
switch (static_cast<ValueType>(tag & 0xff)) { // 最后8-bit是valueType
case kTypeValue: {
Slice v = GetLengthPrefixedSlice(key_ptr + key_length);
value->assign(v.data(), v.size());
return true;
}
case kTypeDeletion:
*s = Status::NotFound(Slice());
return true;
}
到这里 Memtable 的实现已经简要分析完了。关于 Memtable 的内容其实还有两块没有说明:一是 KeyComparator 的实现细节,这个自行看源码和注释不难理解,这里就省掉了;二是类型为 kTypeDeletion 的 key/value 到底是什么时候从 Memtable 中删除,这个将会在后面讲到 SSTable 和 compaction 的时候解释。