Python 中的方法解析顺序(Method Resolution Order, MRO)定义了多继承存在时 Python 解释器查找函数解析的正确方式。当 Python 版本从 2.2 发展到 2.3 再到现在的 Python 3,MRO算法也随之发生了相应的变化。这种变化在很多时候影响了我们使用不同版本 Python 编程的过程。
什么是 MRO
MRO 全称方法解析顺序(Method Resolution Order)。它定义了 Python 中多继承存在的情况下,解释器查找函数解析的具体顺序。什么是函数解析顺序?我们首先用一个简单的例子来说明。请仔细看下面代码:
class A():
def who_am_i(self):
print("I am A")
class B(A):
pass
class C(A):
def who_am_i(self):
print("I am C")
class D(B,C):
pass
d = D()
如果我问在 Python 2 中使用 D 的实例调用 d.who_am_i(),究竟执行的是 A 中的 who_am_i() 还是 C 中的 who_am_i(),我想百分之九十以上的人都会不假思索地回答:肯定是 C 中的 who_am_i(),因为 C 是 D 的直接父类。然而,如果你把代码用 Python 2 运行一下就可以看到 d.who_am_i() 打印的是 I am A。
是不是觉得很混乱很奇怪?感到奇怪就对了!!!
这个例子充分展示了 MRO 的作用:决定基类中的函数到底应该以什么样的顺序调用父类中的函数。可以明确地说,Python 发展到现在,MRO 算法已经不是一个凭借着执行结果就能猜出来的算法了。如果没有深入到 MRO 算法的细节,稍微复杂一点的继承关系和方法调用都能彻底绕晕你。
New-style Class vs. Old-style Class
在介绍不同版本的 MRO 算法之前,我们有必要简单地回顾一下 Python 中类定义方式的发展历史。尽管在 Python 3 中已经废除了老式的类定义方式和 MRO 算法,但对于仍然广泛使用的 Python 2 来说,不同的类定义方式与 MRO 算法之间具有紧密的联系。了解这一点将帮助我们从 Python 2 向 Python 3 迁移时不会出现莫名其妙的错误。
在 Python 2.1 及以前,我们定义一个类的时候往往是这个样子(我们把这种类称为 old-style class):
class A:
def __init__(self):
pass
Python 2.2 引入了新的模型对象(new-style class),其建议新的类型通过如下方式定义:
class A(object):
def __init__(self):
pass
注意后一种定义方式显示注明类 A 继承自 object。Python 2.3 及后续版本为了保持向下兼容,同时提供以上两种类定义用以区分 old-style class 和 new-style class。Python 3 则完全废弃了 old-style class 的概念,不论你通过以上哪种方式书写代码,Python 3 都将明确认为类 A 继承自 object。这里我们只是引入 old-style 和 new-style 的概念,如果你对他们的区别感兴趣,可以自行看 stackoverflow 上有关该问题的解释。
理解 old-style class 的 MRO
我们使用前文中的类继承关系来介绍 Python 2 中针对 old-style class 的 MRO 算法。如果你在前面执行过那段代码,你可以看到调用 d.who_am_i() 打印的应该是 I am A。为什么 Python 2 的解释器在确定 D 中的函数调用时要先搜索 A 而不是先搜索 D 的直接父类 C 呢?
这是由于 Python 2 对于 old-style class 使用了非常简单的基于深度优先遍历的 MRO 算法(关于深度优先遍历,我想大家肯定都不陌生)。当一个类继承自多个类时,Python 2 按照从左到右的顺序深度遍历类的继承图,从而确定类中函数的调用顺序。这个过程具体如下:
- 检查当前的类里面是否有该函数,如果有则直接调用。
- 检查当前类的第一个父类里面是否有该函数,如果没有则检查父类的第一个父类是否有该函数,以此递归深度遍历。
- 如果没有则回溯一层,检查下一个父类里面是否有该函数并按照 2 中的方式递归。
上面的过程与标准的深度优先遍历只有一点细微的差别:步骤 2 总是按照继承列表中类的先后顺序来选择分支的遍历顺序。具体来说,类 D 的继承列表中类顺序为 B, C,因此,类 D 按照先遍历 B 分支再遍历 C 分支的顺序来确定 MRO。
我们继续用第一个例子中的函数继承图来说明这个过程:
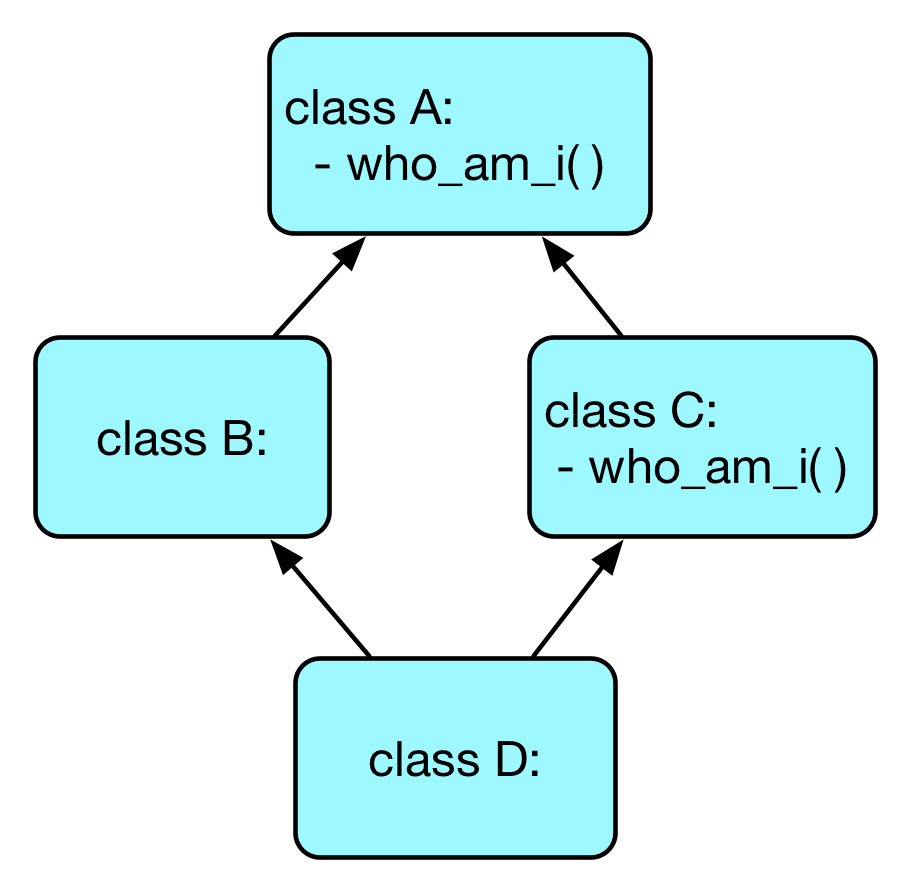
按照上述深度递归的方式,函数 d.who_am_i() 调用的搜索顺序是 D, B, A, C, A。由于一个类不能两次出现,因此在搜索路径中去除掉重复出现的 A,得到最终的方法解析顺序是 D, B, A, C。这样一来你就明白了为什么 d.who_am_i() 打印的是 I am A 了。
在 Python 2 中,我们可以通过如下方式来查看 old-style class 的 MRO:
>>> import inspect
>>> inspect.getmro(D)
理解 new-style class 的 MRO
从上面的结果可以看到,使用深度优先遍历的查找算法并不合理。因此,Python 3 以及 Python 2 针对 new-style class 采用了新的 MRO 算法。如果你使用 Python 3 重新运行一遍上述脚本,你就可以看到函数 d.who_am_i() 的打印结果是 I am C。
>>> d.who_am_i()
I am C
>>> D.__mro__
(<class 'test.D'>, <class 'test.B'>, <class 'test.C'>, <class 'test.A'>, <class 'object'>)
新算法与基于深度遍历的算法类似,但是不同在于新算法会对深度优先遍历得到的搜索路径进行额外的检查。其从左到右扫描得到的搜索路径,对于每一个节点解释器都会判断该节点是不是好的节点。如果不是好的节点,那么将其从当前的搜索路径中移除。
那么问题在于,什么是一个好的节点?我们说 N 是一个好的节点当且仅当搜索路径中 N 之后的节点都不继承自 N。我们还以上述的类继承图为例,按照深度优先遍历得到类 D 中函数的搜索路径 D, B, A, C, A。之后 Python 解释器从左向右检查时发现第三个节点 A 不是一个好的节点,因为 A 之后的节点 C 继承自 A。因此其将 A 从搜索路径中移除,然后得到最后的调用顺序 D, B, C, A。
采用上述算法,D 中的函数调用将优先查找其直接父类 B 和 C 中的相应函数。
C3线性化算法
上一小结我们从直观上概述了针对 new-style class 的 MRO 算法过程。事实上这个算法有一个明确的名字 C3 linearization。下面我们给出其形式化的计算过程。
在介绍算法之前,我们首先约定需要使用的符号。我们用 $C_{1}C_{2} \cdots C_{N}$ 表示包含 N 个类的列表,并令
\[head(C_{1}C_{2} \cdots C_{N})=C_{1}\] \[tail(C_{1}C_{2} \cdots C_{N})=C_{2}C_{3} \cdots C_{N}\]为了方便做列表连接操作,我们记:
\[C_{1} + (C_{2}C_{3} \cdots C_{N}) = C_{1}C_{2} \cdots C_{N}\]假设类 $C$ 继承自父类 $B_{1}, \cdots, B_{N}$,那么根据 C3 线性化,类 $C$ 的方法解析列表通过如下公式确定:
\[L[C(B_{1} \cdots B_{N})] = C + merge(L[B_{1}], \cdots, L[B_{N}], B_{1} \cdots B_{N})\]这个公式表明 $C$ 的解析列表是通过对其所有父类的解析列表及其父类一起做 $merge$ 操作所得到。
接下来我们介绍 C3 线性化中最重要的操作 $merge$,该操作可以分为以下几个步骤:
- 选取 $merge$ 中的第一个列表记为当前列表 $K$。
- 令 $h = head(K)$,如果 $h$ 没有出现在其他任何列表的 $tail$ 当中,那么将其加入到类 $C$ 的线性化列表中,并将其从 $merge$ 中所有列表中移除,之后重复步骤 2。
- 否则,设置 $K$ 为 $merge$ 中的下一个列表,并重复 2 中的操作。
- 如果 $merge$ 中所有的类都被移除,则输出类创建成功;如果不能找到下一个 $h$,则输出拒绝创建类 $C$ 并抛出异常。
上面的过程看起来好像很复杂,我们用一个例子来具体执行一下,你就会觉得其实还是挺简单的。假设我们有如下的一个类继承关系:
class X():
def who_am_i(self):
print("I am a X")
class Y():
def who_am_i(self):
print("I am a Y")
class A(X, Y):
def who_am_i(self):
print("I am a A")
class B(Y, X):
def who_am_i(self):
print("I am a B")
class F(A, B):
def who_am_i(self):
print("I am a F")
首先我们有 $L[X] = X$,$L[Y] = Y$,然后立即可以得到:
\[L[A] = A + merge[L[X], L[Y], X, Y] = [A, X, Y]\] \[L[B] = B + merge[L[Y], L[X], Y, X] = [B, Y, X]\]根据公式:
\[L[F] = F + merge[L[A], L[B], A, B] = F + merge[[A, X, Y], [B, Y, X], A, B]\]我们首先选取 $h = head(L[A]) = A$,发现 $A$ 可以加入到类 $C$ 的解析列表中(同时将 A 从其他列表中删去),所以得到:
\[L[F] = [F, A] + merge[[X, Y], [B, Y, X], B]\]之后选取 $h = head(L[A]) = X$,发现 $X$ 不能满足要求(因为$X$ 在 $L[B]$ 的 $tail$ 中出现),所以根据步骤 3 选取下一个列表并令 $h = head(L[B]) = B$,然后将 $B$ 加入到类 $C$ 的解析列表中得到:
\[L[F] = [F, A, B] + merge[[X, Y], [Y, X]]\]接下来按照算法流程应该选取 $h = head(L[B]) = Y$,很显然 $Y$ 并不能满足要求,此时由于 $merge$ 中没有下一个列表了,所以不能继续选择 $h$,所以根据步骤 4 算法输出类 F 创建失败并抛出异常。如果你用 new-style class 的方式执行一下上面的代码,你就会发现 Python 解释器将不允许你创建类 F:
Traceback (most recent call last):
File "test.py", line 17, in <module>
class F(A, B):
TypeError: Cannot create a consistent method resolution
order (MRO) for bases X, Y
参考文献
- Python Tutorial: Understanding Python MRO - Class search path
- The Python 2.3 Method Resolution Order
- C3 linearization