程序设计语言是向人和计算机描述计算过程的记号。如我们所知,这个世界依赖于程序设计语言,因为在所有计算机上运行的所有软件都是用某种程序设计语言所编写。但是,在一个程序可以运行之前,它首先需要被翻译成一种能够被计算机识别的形式。
完成这项翻译工作的软件系统被称为编译器。
编译型语言 VS 解释型语言
尽管在任何一门有关编译原理的课程上都会提到编译和解释的概念,但是不是每个人都能清楚地说明这两者之间的区别。下图从用户的角度给出了编译器和解释器处理用户程序的基本过程。
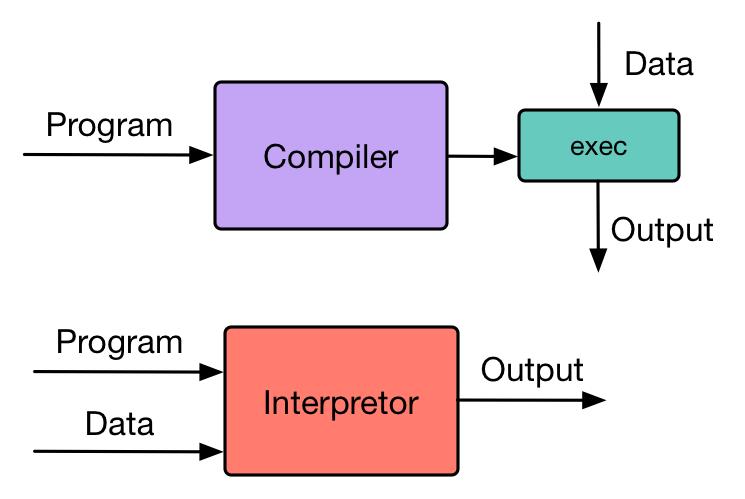 图1:Compiler vs Interpretor
图1:Compiler vs Interpretor
- 编译器读取用户使用某种语言编写的 源程序 ,并把改程序翻译成为一个等价的,用另一种语言编写的 目标程序 ,用户可以给定数据,并调用目标程序产生输出。
- 解释器并不通过翻译的方式生成目标程序。从用户的角度来看,解释器直接利用用户提供的输入来执行源程序文件中指定的操作。
按照上面的定义,我们通常所用的 Python 是一种解释性语言,但事实上 Python 兼具了编译和解释的过程。一个 Python 程序首先被编译成为 Python 字节码,然后通过 Python 虚拟机解释执行。
编译的过程
对于用户来讲,编译器成为了源语言和目标语言之间的黑盒子。如果我们把这个黑盒子揭开,可以看到编译器内部按照顺序完成了下图中的七个步骤:
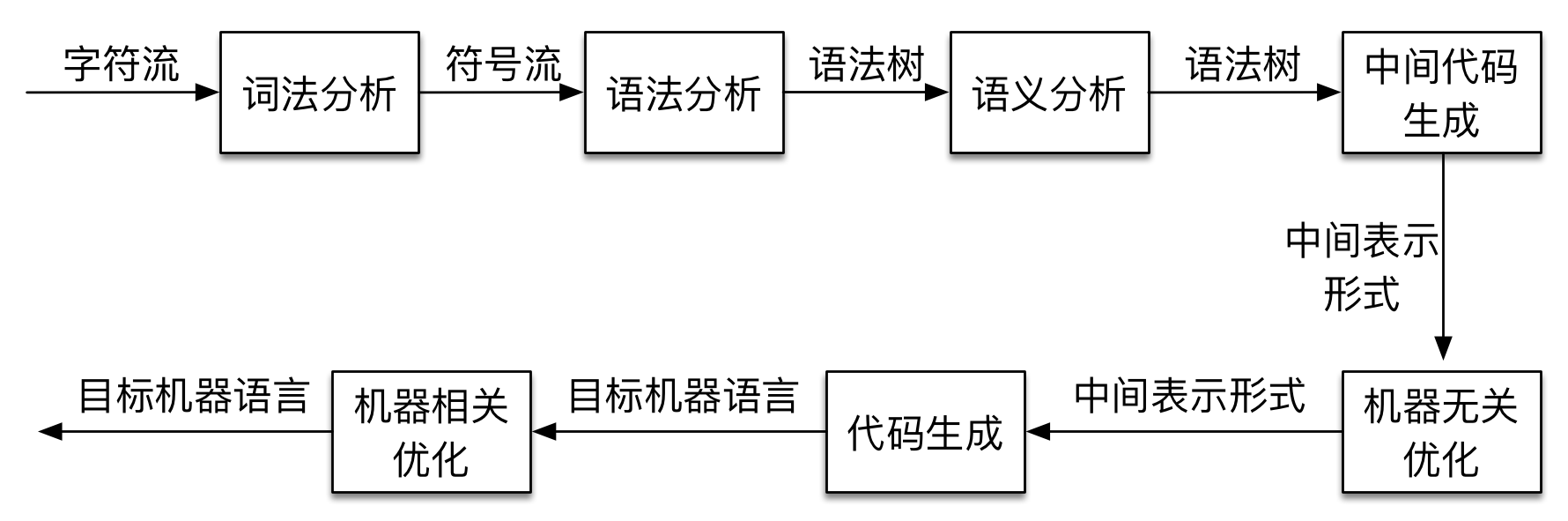 图2:编译的过程
图2:编译的过程
这七个步骤可以分为两个部分,上面四个步骤我们可以称为分析,也就是通常所说的编译器前端,后面三个步骤则称为综合,也就是编译器的后端。
编译器的前端把源文件分解称为多个组成要素,并在这个要素之间添加上语法结构,之后生成一个该源程序的中间表示。至于这个中间表示,可以是一种抽象的语言描述,也可以是一种其他语言(早期的 C++ 编译器前端就直接将 C 语言作为中间表示)。
从这个简单的描述可知,我们平时编程中所出现的打字错误,语法错误或者语义不一致等将都由编译器前端负责检查。另外需要注意的是,上图中忽略了一个非常重要的内容—符号表,事实上前端会收集代码中的各种组成信息并将其存入到符号表中。符号表和中间表示将一同送入到编译器后端。
后端首先将接收到的中间形式进行机器无关优化,然后根据符号表和中间表示形式生成最终的目标机器代码。一般现代编译器还需要对目标机器代码进行平台相关优化,之后我们才能得到最终的目标代码。
在编译器的前后端架构调整方面,Apple 是一个很好地例子。MAC OS 从诞生到现在,一共产生过三种针对 C-like 语言的编译器模型。这三种模型如下表:
| Compiler | front-end | optimizer | generator |
|---|---|---|---|
| GCC | GCC front-end | GCC optimizer | GCC code-generator |
| LLVM-gcc | GCC front-end | LLVM optimizer | LLVM code-generator |
| Clang | LLVM front-end | LLVM optimizer | LLVM code-generator |
实际上,Apple 进行这样的调整是为了实现一个易于调试,代码生成质量高,编译速度快的编译器。这个例子也充分的说明了将编译器划分为前端和后端的好处:通过降低前端和后端的耦合度,从而方便地实现编译器的扩展升级和自由配置。
词法分析
简单而言,词法分析完成两件事情:
- 通过从左往右的读入源程序内容,将源程序划分成为一个个词素(注意每个词素都是一个字符串)。之后将根据不同的词素将其归为不同的词法单元(token)。词法分析中的 token 可以记为一个二元组
<token_class, token_value>, token 的种类比如标识符(Identifier),关键字(keyword),整数(integer),空白符(whitespace)等,token 的值即为词素。 - 利用『向前看(lookahead)』操作来确定当前的词素是否结束以及下一个词素是否开始。
下面用一个简单的例子来说明词法分析的作用,比如 C++ 语言中的语句 int a = 1; 经过词法分析之后可以得到下面几个 token:<keyword, "int">,<identifier, "a">,<operator, "=">,<interger, "1">,<operator, ";">。这些 token 将被送入到语法分析器中供语法分析器使用。
为了完成将源程序划分为 token 的任务,词法分析器需要实现以下几个步骤:
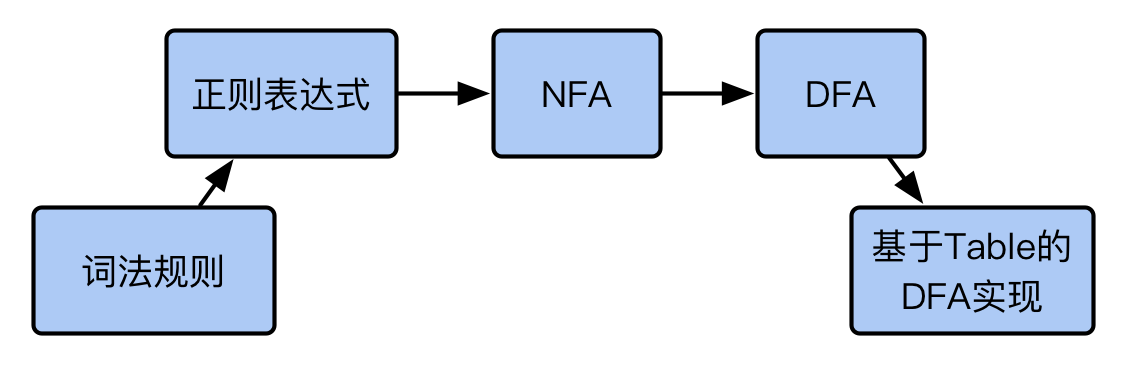 图3:词法分析的基本步骤
图3:词法分析的基本步骤
首先,我们需要有描述词法的规则,这种规则告诉我们什么样的词法才是合法的。我们可以通过正则表达式来描述我们的词法规则。然后我们需要将正则表达式转化成为一个非确定性有穷状态机(NFA),通过NFA我们才能在程序上模拟词法分析的过程。由于NFA执行速度很慢,我们需要将NFA转换成为一个确定性的有穷状态机(DFA)。这就是实现词法分析的主要几个步骤。
正则表达式
正则表达式是词法准则最好的表现形式。正则表达式在语言层面上由两个部分构成:
- 基本单元:任意单个字符 $c$ 组成的集合以及空字符 $\epsilon$ 集合.
- 基本操作:
- 合并(Union):$A+B = \lbrace a \, \vert \, a \in A \rbrace \cup \lbrace b \, \vert \, b \in B \rbrace$
- 连接(Concatenation):$AB = \lbrace ab \, \vert \, a \in A, b \in B \rbrace$
- 迭代(Iteration):$A^{*} = {\cup}_{i \ge 0}A^{i}$
通过上述的正则语言,我们可以轻松构建程序中所有的词法准则。例如:
- 关键字
if可以直接通过单个字母i和f通过连接操作而成; - 任意长度的数字可以表示为 $[0\textit{-}9]^{*}$;
- 标识符可以表示为 $[ \_a\textit{-}zA\textit{-}Z][ \_a\textit{-}zA\textit{-}Z0\textit{-}9]^{*}$;
正则表达式仅仅是用来表示语言规则的一种形式。为了让机器理解正则表达式,我们需要通过程序来实现一种与正则表达式等价的结构。这种结构就是我们后面需要讲的非确定性有穷自动机(Non-deterministic Finite Automaton)和确定性有穷自动机(Deterministic Finite Automaton)。
自动机
一个有穷自动机需要包含以下几种元素:
- 一个输入字符集 $\Sigma$
- 一个有穷的状态集合 $\mathcal{S}$
- 一个起始状态 $n$
- 一个终止状态集合 $\mathcal{F} \subset \mathcal{S}$
- 一系列状态转换 $state \stackrel{input}{\longrightarrow} state$
确定性的有穷自动机还需要满足:1)对于每一个状态而言,一个输入只能确定唯一的一个状态转换;2)没有 $\epsilon\textit{-}moves$。 相比较而言,非确定性有穷自动机则满足:1)在某个状态针对同一个输入可以执行多个不同的状态转换;2)可以有 $\epsilon\textit{-}moves$。
上面所说的 $\epsilon\textit{-}moves$ 是一种特殊的状态转换。可以表示为 $state \stackrel{\epsilon}{\rightarrow} state$,即不需要接受输入字符也可以产生状态转换。从本质上而言,DFA 和 NFA 对于正则表达式的识别能力是完全一致的。但是 NFA 的特点决定了其状态空间简单,DFA 的特点决定了其执行速度很快,这点在后面的讲解中就会体现出来。
正则语言到 NFA
从正则语言转换到 NFA 是一个简单容易的过程。根据正则语言的定义,我们只需要明确三种操作合并,连接和迭代所对应的 NFA,则可以通过递归的方式实现任何正则表达式的 NFA。下图展示了三种操作所对应的 NFA。
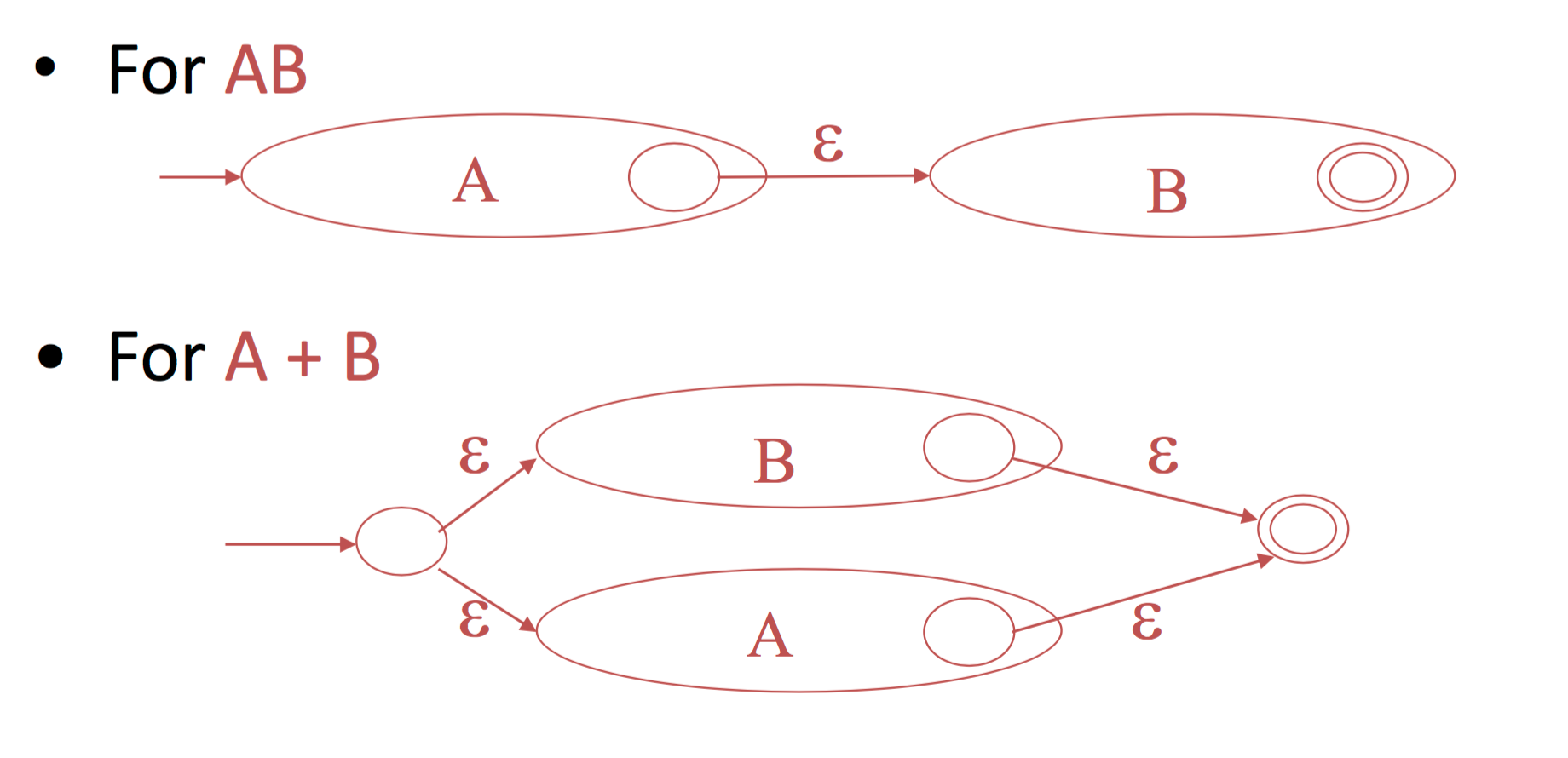
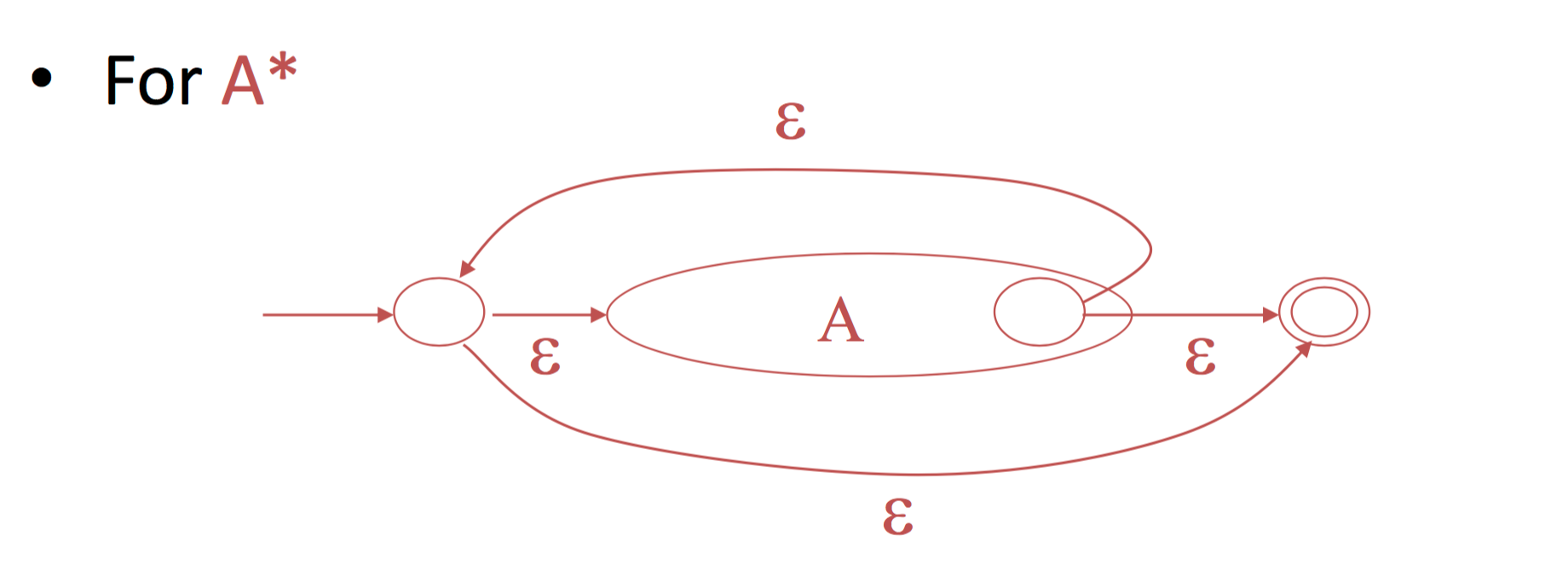 图4:正则表达式生成 NFA
图4:正则表达式生成 NFA
由于 $\epsilon\textit{-}moves$ 赋予了 NFA 从一个状态同时转到多个状态的可能性,从正则语言转到 NFA 将变得非常简单。上图中的内容无需过多解释,你只要沿着图中的状态机顺序走一遍就能很清楚为什么这个转换是等价的。
NFA 到 DFA
我们首先给出 $\epsilon\textit{-}closure$的定义。$\epsilon\textit{-}closure(s)$ 为从状态 $s$ 开始,通过 $\epsilon\textit{-}moves$ 所能到达的所有状态的集合(包括状态$s$本身)。这么说可能不是很直观,那我们给个例子:
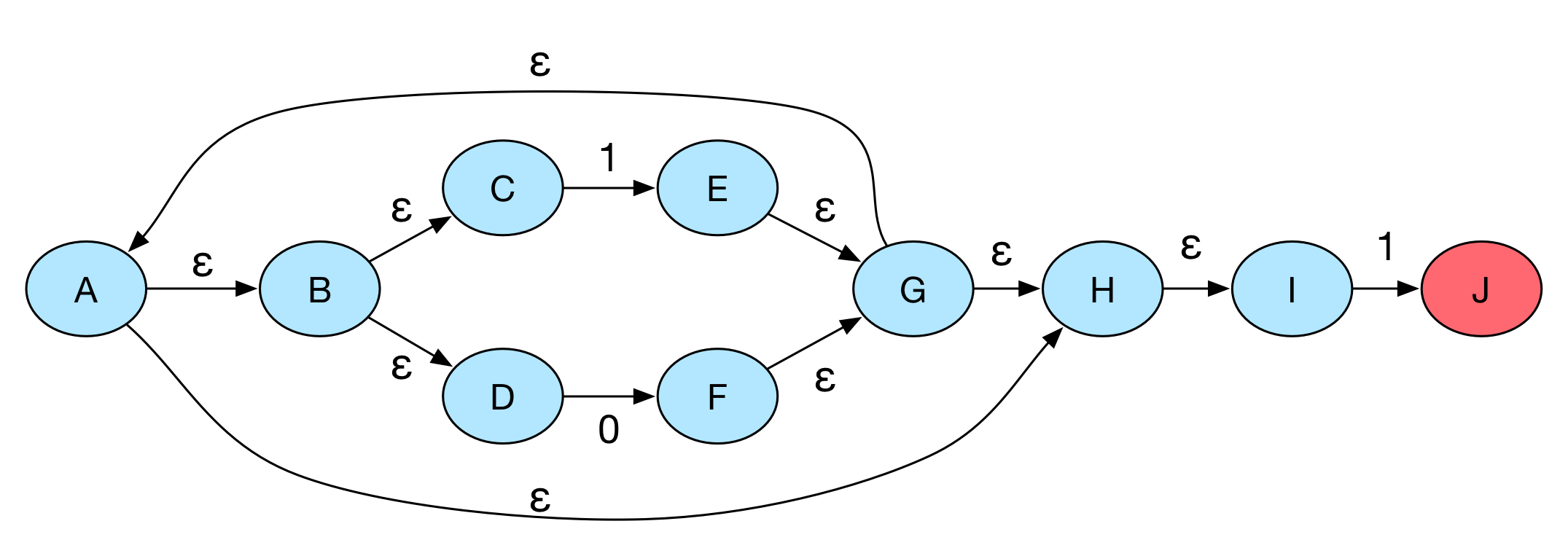
根据闭包的定义,我们可以得到(自己测试吧):
- $\epsilon\textit{-}closure(B) = \lbrace B, C, D \rbrace$
- $\epsilon\textit{-}closure(G) = \lbrace A, B, C, D, G, H, I \rbrace$
接下来我们定义一个运算 $a(X) = \lbrace y \, \vert \, x \in X \wedge x \stackrel{a}{\rightarrow} y \rbrace$。该运算表示从状态集合 $X$ 中的状态经过输入 $a$ 之后可以得到的状态集合。
现在我们就可以定义 NFA 转换到等价的 DFA 的过程了,经过转换的 DFA 满足如下条件:
- 状态集合:$subsets \, of \mathcal{S}$, $\mathcal{S}$ 是 NFA 的状态集合。
- 初始状态:$ \epsilon\textit{-}closure(s)$,$s$ 是 NFA 的起始状态。
- 终止状态:$\lbrace X \, \vert \, X \wedge \mathcal{F} \ne \phi \rbrace$,其中$\mathcal{F}$是 NFA 的终止状态集合。
- 状态转换操作:$X \stackrel{a}{\rightarrow} Y \quad \textit{if} \quad Y = \epsilon\textit{-}closure(a(X))$。
上面的NFA经过转换之后得到的 DFA 如下:
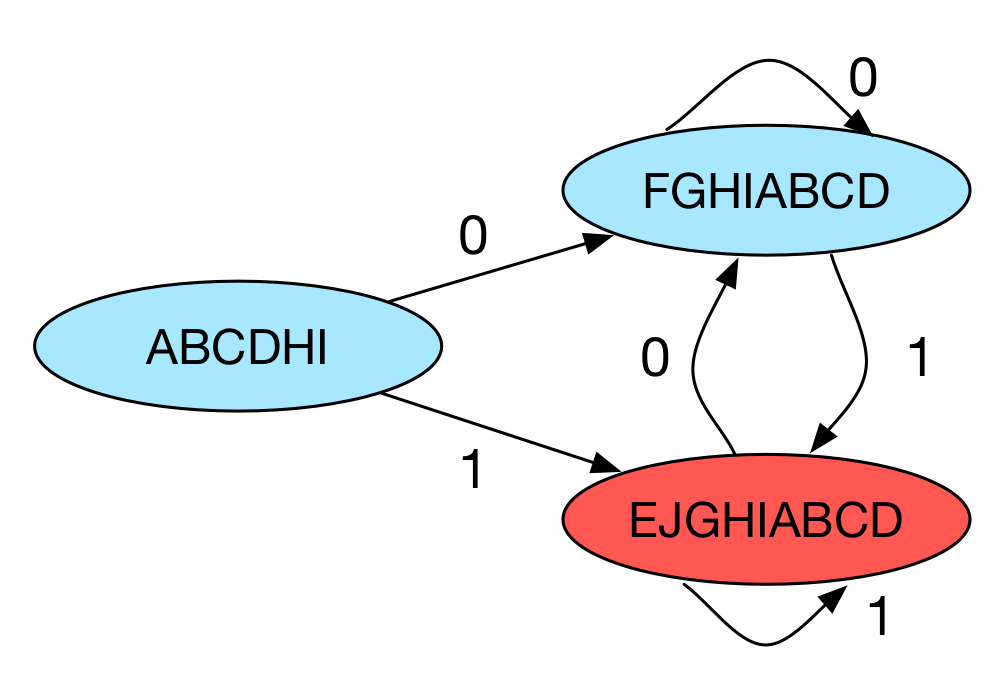
从这个例子中我们可以看到,DFA 中所有的状态转换路径都是唯一确定的,这决定了 DFA 的执行速度通常将比NFA快很多。然而,由于 DFA 的每个状态都是 NFA 状态集合的一个子集,在大多情况下由NFA转换成为 DFA 将会导致状态数量呈现指数次方的增长。假如状态数量地增长达到一定程度导致状态表超过主存容量的时,DFA 真正的运行时间将会加上读取磁盘的时间,这将导致其执行时间成倍地增加。
因此,在现代有关词法分析的工具中,应该通过 NFA 模拟还是通过 DFA 模拟正则表达式是根据具体的使用场景来决定的。对于编译器中的词法分析器,显然使用 DFA 是更好的方式,因为其正则表达式基本固定,并且词法分析过程需要被频繁地调用。这种情况下将 NFA 转换成为 DFA 的开销是值得的。相比之下,对于另外的词法处理工具,例如 grep,由于需要用户指定不同的正则模式,其直接模拟 NFA 来执行将会是更好的选择。
词法分析实现
如果你想研究词法分析的实现过程,请参照 flex(C),JFlex(Java) 以及 PLY(Python)。