这几天一直在看sigcomm14上面的文章,总体感觉就是今年Application-aware networking这个topic突然就火了。在我看来今年在此领域最引人关注的文章是来自Mosharaf Chowhury的Varys[1](B.T.W M.Chowhury这位Berkeley的大牛相当猛,最近几年基本每年都有1到2篇的sigcomm)。Varys延续了MC在2012年HotNets上面发表的coflow (有关coflow的工作模型,以后有时间再写吧)的工作,主要针对并行的data-sensitive的应用,比如MapReduce进行相关的流处理优化。 这篇文章中通过inter-Coflow scheduling来提高应用通讯性能的思想,提供了很多关于Application-aware networking的直观启示。为了深入地理解一下MapReduce的工作模型,以及其具有的Application Characteristics,打算仔细学习一下Hadoop的相关内容。相信对以后的生涯一定会产生帮助。
什么是Hadoop?
说到什么是Hadoop,就不得不提google在2003年以及2004年间发表的那几篇掉咋天的文章“The Google File System”和”MapReduce: Simplified Data Processing on Large Clustres”。就是这两篇文章直接促成了Hadoop的诞生。当时的开源搜索引擎之父Doug Cutting为了提高集群的性能正一筹莫展之时,看到了google的这两篇文章。顿时Cutting犹如拨云见日,花了两年的时间开发了Hadoop的前身。后来Doug Cutting加入Yahoo!,这个项目也被单独剥离出来开发,成为了现在的Hadoop。有关Hadoop是怎么写出来的就不多说了,感兴趣的可以自己查查野史。但是需要说明的是Hadoop并不是大象的意思,只是Doug Cutting的小孩给他的一个大象玩具起的名字而已。
Hadoop的架构
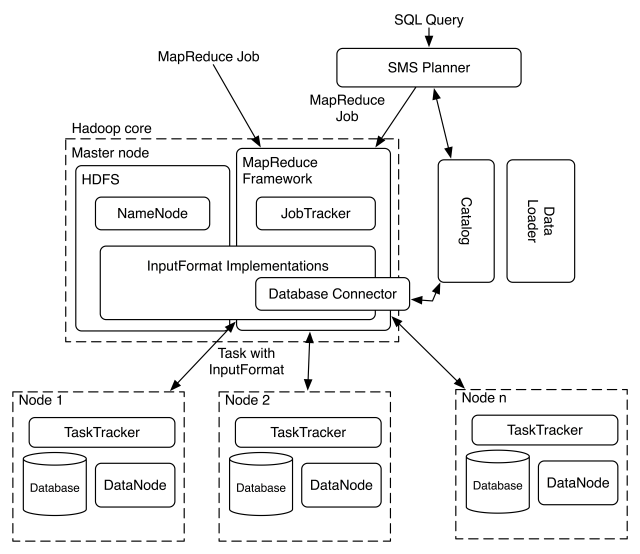
Hadoop使用Master/Slave的架构来运行分布式程序和管理分布式存储。Master节点和Slave节点上都运行了一系列的daemon程序,如图1。这些daemon主要包括:
- NameNode:运行在Master节点上,负责记录文件是怎么分块的,以及分块数据都存储到了那些节点上。他的主要功能是对IO以及内存进行管理。
- DataNode:运行在Slave节点上,负责同NameNode进行通讯,并把数据块读写到本地文件系统。
- Secondary NameNode:顾名思义就知道此模块是NameNode的容错模块,负保存整个HDFS的快照用以故障恢复。当然,如果NameNode节点出错,SNN将会接手NN的工作。
- JobTracker:运行在Master节点上,负责联系应用程序和Hadoop。用户提交的代码由JobTracker负责决定那些文件将被处理,以及Tasks应该放到哪些节点上进行处理。
- TaskTracker:运行在Slave节点上,与负责存储的DataNode进行合作,负责执行由JobTracker分配的Task。主义的是,一个TaskTracker能够同时启动多个jvm运行多个Tasks。
在Archlinux下安装Hadoop
安装ssh并启动
sudo pacman -S openssh
sudo systemctl start sshd.service
sudo systemctl enable sshd.service
配置ssh无密码登陆
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
通过
ssh localhost
检测是否配置成功
下载并安装Hadoop
直接在Hadoop官网下载最新的stable版本并且解压。 Hadoop有三种安装模式。在单机模式下,Hadoop作为一个非分布式环境运行,适合开始时调试工作使用;伪分布式模式工作在单个机器上,使用不同的Java进程模拟NameNode,DataNode,JobTracker和TaskTracker等等;集群模式则需要配置整个Cluster。这里我们使用伪分布式模式来安装配置Hadoop,并且试着运行第一个简单的程序。
首先使用编辑器编辑文件etc/hadoop/hadoop-env.sh,添加JAVA_HOME的环境变量
JAVA_HOME=/the/path/to/your/java_home
然后试着执行:
$ bin/hadoop
这将会显示出有关Hadoop这个脚本的使用手册信息。
接下来配置文件etc/hadoop/core-site.xml,设置文件系统地址,其中端口号可以更改
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
配置etc/hadoop/hdfs-site.xml,设置数据的备份书目:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
之后你就可以格式化文件系统了:
$ bin/hdfs namenode -format
启动NameNode节点以及DataNode节点:
$ sbin/start-dfs.sh
你可以通过浏览器来浏览NameNode的信息:
http://localhost:50070/
接下来我们利用Hadoop提供的wordcount样例程序来尝试运行第一个Hadoop实例。首先创建文件目录:
$ bin/hdfs dfs -mkdir /user
然后在Hadoop根目录下创建一个目录,假设名为test,并且在test内创建两个文件file1.txt和file2.txt,其中的内容为:
file1.txt : Hello World file2.txt : Hello Hadoop
之后将test目录加入到Hadoop的文件系统当中去,并将其重命名为input
$ bin/hdfs dfs -put test input
注意:这个时候很有可能会出现及其容易出现的错误:“There are 0 datanode(s) running and no node(s) are excluded in this operation.”。如果你运行:
$ bin/hdfs dfsadmin -report
将会看到以下信息:
Decommission Status : Normal
Configured Capacity: 0 (0 B)
DFS Used: 0 (0 B)
Non DFS Used: 0 (0 B)
DFS Remaining: 0 (0 B)
DFS Used%: 100.00%
DFS Remaining%: 0.00%
如果你再通过http://localhost:50070/查看live node,发现显示为0。那么恭喜你,你的DataNode启动不成功,无法同NameNode进行通讯。不要惊慌,这种错误的根源在于你有可能重复执行了前面所说的文件系统格式化命令。事实上,每次格式化之后namenode 都分配新的namespaceID 而datanode 还保留着原来的namespaceID,这会造成namenode 的namespaceID 和 datanode 的namespaceID 不同,从而导致DataNode启动不了。你可以采用两种方案解决问题:
- 删除/tmp目录下已经生成的文件系统,这会导致所有数据的丢失。(不过没关系,本来就是重新安装)
- 修改DataNode的namespaceID。对应于修改/tmp/hadoop-xxx/dfs/data/current/VERSION的内容。数据也会丢失。(真是丧(gan) 心(de) 病(piao) 狂(liang))
接下来就可以真正的执行wordcount程序了:
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount input out
如果屏幕上又弹出一大堆异常,那么八成是以下的原因: Resources are low on NN. Please add or free up more resources then turn off safe mode manually. NOTE: If you turn off safe mode before adding resources, the NN will immediately return to safe mode.通过执行:
$ bin/hdfs dfsadmin -safemode leave
使得NameNode推出safe mode。
执行完成之后的结果都存储在HDFS中的out目录中,通过下面的指令显示执行结果:
$ bin/hadoop dfs -cat out/*
如果看到结果
[wky@wky hadoop-2.5.0]$ bin/hdfs dfs -cat out/*
hadoop 1
hello 2
world 1
那么恭喜,人生的Hadoop旅程已经正式开始了。