最近打算为内部的 KV 系统增加分布式事务的功能,因此再次回过头来细细看了 Google Percolator、Yahoo Omid 三部曲等相关论文。尽管先前对分布式事务的概念和实现方案已经有所了解,但此次详细回顾仍然收获良多,对于 2PC 在分布式 KV 上的抽象、设计取舍以及实现方式都有了新的认识,这里做一个记录以备忘。
分布式事务抽象
提到分布式事务,首先想到的肯定是两阶段提交(2PC)协议。本文不会详细地介绍两阶段提交协议的理论内容,而是针对 2PC 在 KV 领域的实现方案做一个总结。
隔离级别
一个可靠的事务系统能够提供 ACID 的特性。其中 Isolation 定义了并发事务发生时系统的具体表现。在传统的数据库领域,Isolation 可被定义为 Read Uncommitted、Read Committed、Repeatable Read、Serializable 以及 Snapshot Isolation 等级别。而分布式事务方案 Omid 的作者也曾在 2012 年针对 snapshot isolation 扩展出了 write-snapshot isolation 的概念,但不知为何该概念在随后的 Omid 设计中并未体现出来。
针对 KV 的分布式事务方案主要提供 Snapshot Isolation (e.g. Percolator, Omid etc.)和 Serializable (cockroachDB) 两种隔离级别。相比于 Serializable,Snapshot Isolation 仅仅检测 Write-Write confliction 而并不检测 Read-Write confliction,因此可能会产生 write skew 现象。但相比而言,支持 Snapshot Isolation 的系统不会中断只读事务,因此也会提供更好的事务并发性。
满足 Snapshot Isolation 级别的事务系统需要具备如下要求:
- 每一个事务都有开始时间戳 $t_s$ 以及提交时间戳 $t_c$;
- 需要检测并避免 Write-Write 冲突(包括 RW-RW 冲突);
- 读事务都满足 Snapshot-read:即对于一个事务 T1 而言,所有满足$t_c <= T1.t_s$ 的事务的修改都对 T1 可见,所有 $t_c > T1.t_s$ 的事务修改都对 T1 不可见;
对于任何两个写事务 T1 和 T2, Write-Write 冲突定义如下:
- 存在 Spatial overlap,即 T1 事务的 Write Set 与 T2 事务的 Write Set 有交集;
- 存在 Temporal overlap,一个事务在另一个事务执行过程中提交,即 $T1.t_s < T2.t_c$ 并且 $T2.t_s < T1.t_c$;
如果要求系统满足 Serializable,那么上述关于 Snapshot Isolation 的的要求 2 中,不仅要检测 Write-Write 冲突,也要检测 Read-Write 冲突。
事务系统抽象
上述定义中给出了事务系统的隔离级别定义。事实上,实际中的存储系统不仅仅需要满足一定的隔离级别,还需要满足一致性要求。关于隔离级别和一致性要求的关系,大部分人都会混淆,认为其具有相似的概念,这其实是大错特错的。这里给出一个 Jepsen Test 官网上面的一张图,这张图是我见过最好的描述隔离性以及一致性关系的图片:
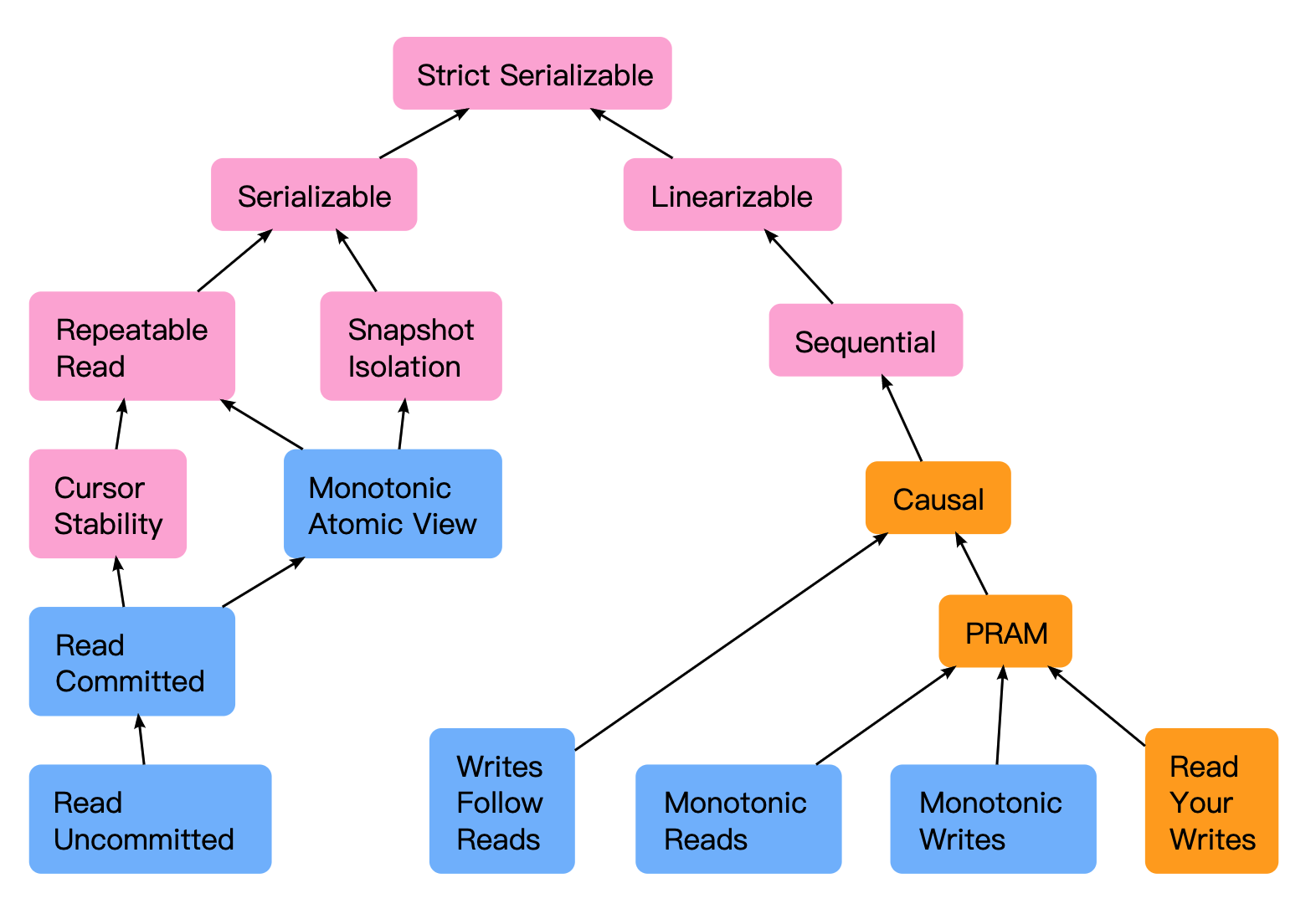
这张图中树的根节点 Strict Serializable 代表了最强的一致性和隔离性要求,Spanner 即为满足该条件的分布式数据库系统。根节点的左枝描述数据库领域隔离性的要求,而根节点的右枝描述并行计算领域对一致性的要求。
从实际的角度出发,事务系统满足 linearizability 是很直观的要求。对于 Client 而言,任何读事务都应该看到已经提交过的写事务。因此为了为了实现一个满足 linearizability 以及 SI 的分布式事务系统,需要解决两个关键的问题:
- 如何为每个事务获取满足条件的时间戳;
- 如何检测并发事务之间的 Write-Write 冲突;
针对第 1 点如何获得时间戳使得系统满足 linearizability,最简单直观的思路是设置一个集中式的 Timestamp server oracle (TSO),所有事务的 start_ts 以及 commit_ts 都需要向 TSO 发起申请,从而保证 linearizability(Percolator、Omid 以及 Tephra 都采用了该方案)。分布式的时间戳获取方式往往需要额外的硬件或者逻辑来保证,典型的如 Google Spanner 的 TrueTime 以及 CockroachDB 使用的基于 Hybrid Logic Clock 和 NTP 的方案。本文中,我们采用集中式的 TSO 方案来简化事务系统的分析。
我们使用事务的开始时间戳 $t_s$ 作为事务ID(等价于事务版本号 version),针对第 2 点如何检测 Write-Write 冲突,事务系统一般需要获得如下元信息:
- 每个事务的写集合(Write Set);
- $L_s$,事务开始时间戳 $t_s$ 的列表;
- $T_c$,事务 ID($t_s$) 到其提交时间戳 $t_c$ 的映射;
假设系统拥有所有写事务的如上元信息,那么由 1 和 3 可得到数据库中任何一个 key 最后的提交时间戳 lastCommit(key)。因此我们可以很容易得到一个简单的集中式的事务冲突检测框架(后面我们也会介绍 Percolator 是如何将集中式的冲突检测转化成为分布式冲突检测):
func CheckWWConflict(tid, WriteSet) -> bool {
for each key k in WriteSet {
if (lastCommit(k) > Ts(tid)) {
// Conflict with other write txns
return true;
}
}
return false;
}
除此之外,分布式事务系统还需要一个可持久化的 Commit Table (CT),其存储事务 $t_s$ 到 $t_c$ 的映射。一旦写入 Commit Table,那么标志着该事务 commit 成功。Commit Table 实际上扮演了分布式事务中的提交点的作用,在做事务 Recover 时,提交点之前的事务都可以 Roll Back,而过了提交点的事务只能 Roll Forward。对于 Percolator 而言,你可以认为其 Commit Table 是分布式存储的,每个写事务 Primary key 的 Write 列的集合即构成了 Percolator 的 Commit Table。
事务基本语义
针对 KV 的事务系统需要提供如下事务操作:
- Begin: Client 通过 Begin 开启一个事务,此时 client 会向中心节点 TSO 获取该事务的开始时间戳 $t_s$,同时也作为该事务的版本号;
- Transactional Writes: 执行事务写操作,针对写集合 Write Set 中的每一个(key, $t_s$),根据事务系统的并发控制机制决定是否需要在该阶段检测事务冲突。如果事务系统采用悲观并发控制,则需要在此时检测当前事务是否与其他并发事务发生冲突,典型的实现如 Percolator,在写入 Data Table 之前,通过每一行的 Lock 列来检测是否发生写冲突。检测通过之后将 (key, value, $t_s$) 写入到 KV 中,并采用某种方式标记该版本为 Intent (Uncommited);
- Transactional Reads: 执行事务读操作,针对读集合 Read Set 中的每一个 key,按照从大到小的顺序,遍历所有小于 $t_s$ 的版本,返回第一个提交版本小于等于 $t_s$ 的 value 和对应的版本,具体过程如下:
- 读取满足 $ver < t_s$ 的最大版本的数据 (key, value, ver);
- 如果读到的数据为 Intent,那么需要在 Commit Table 中查询当前读到的版本 ver 对应的写事务是否已经提交( CT 中是否存在 ver->$t^{ver}_c$ 的映射);
- 如果未提交,则忽略读到的版本的 value(根据不同的实现这里可能需要强制 abort 某些写事务),重复执行 1,读取下一个满足条件的版本;
- 如果 ver 版本对应的写事务已经提交,并且其提交时间戳 $t^{ver}_c$ 小于 $t_s$,那么直接返回 ver 对应读到的 value 和版本号;否则重复操作 1;
- Commit: Commit 操作完成事务的提交。如果系统采用了乐观并发控制,那么写事务的冲突检测将在这一步完成。典型的实现如 Omid, 通过一个中心节点来检测事务冲突,如果检测成功,那么将 commit_ts 返回给 client,由 client 将当前事务写入 Commit Table,标志着事务 commit 成功;同时 client 可以异步的清除先前在 WriteSet 中所有 key 的 Intent 状态。
目前大部分基于中心节点 TSO 的分布式事务系统的设计思想都可以归结为上述的框架,其区别仅在于实现的细节有所差异。下面我们主要介绍两种方案 Google Percolator 以及 Yahoo Omid LL (VLDB18) 。
Percolator 实现
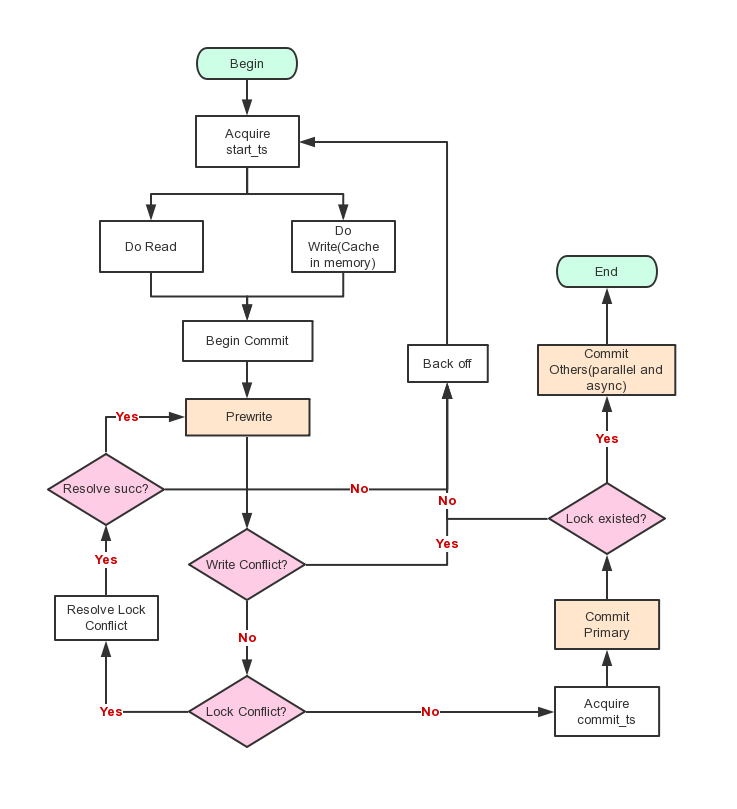
Percolator 为 google 在 2011 年提出的基于 BigTable 的分布式事务系统。其通过在 BigTable 的每一行中额外的增加 Lock 列来实现分布式的冲突检测,并通过另一个 Write 列来实现上述 Commit Table 的功能。Percolator 的大体流程如下图,其理论过程很简单(但工程实现需要大量优化)。这里我们仅通过上述语义框架来阐述 Percolator 的设计思路。
-
Begin: 开启一个事务时,Percolator 会向集中的节点 TSO 申请一个事务开始时间戳 $t_s$,并且以 $t_s$ 作为该事务的事务 ID(版本号),$t_s$ 可以是一个递增的逻辑时间戳。
- Transaction Writes: Percolator 首先在 Write Set 中选取一个 key 作为 Primary,其他的 key 都作为 Secondaries. Percolator 采用悲观并发控制的思想,其在写入阶段就进行冲突检测,也就是论文中的
Prewrite函数的功能。Percolator 会先对 Write Set 中的 Primary key 执行Prewrite,成功后再对剩下的 Secondary keys 做 Prewrite 检查. 针对 key x,Prewrite主要流程如下:- 如果 x 的 Write 列中存在版本号大于 $t_s$ 的值,那么表明有其他写事务在该事务执行过程中提交了(即存在 lastCommit(x) > $t_s$),直接返回事务冲突,Client 进行 Backoff 之后重试;
- 如果 x 的 Lock 列中存在任意版本的数据,那么表明存在执行过程被中断的写事务,返回事务锁冲突;
- 在 x 的 data 列写入数据 (value, $t_s$);
- 在 lock 列写入 Primary key 的位置 ([prim.row, prim.col], $t_s$);
从上述事务写的过程中可以得到几个结论。第一,在上述步骤 2 中,如果 client 异常,那么写事务可能会在某些 key 的 Lock 列中残留有数据,这将导致后续写事务的失败。因此在实际实现中,Client 在开始事务时需要根据事务大小来为 lock 加上 TTL。Client 在进行 Primary 的 Prewrite 检查时,如果其 lock 存在,并且没有超过 TTL,那么当前事务将做 Backoff 之后再进行尝试;否则可以 RollBack 先前的事务,清除掉残留的 lock 数据;如果 Secondaries 的 Prewrite 遇到残留的 lock 并且其 TTL 超时,Client 可以根据其 lock 列中记录索引到 Primary key,并根据 Primary 的状态来决定 RollBack 或者 Commit 先前的事务。因此,Percolator 写事务中的 Primary Key 的 Write 列扮演了 Commit Table 的作用,其决定了该事务的提交点,一旦事务写入 Primary Key 的 write 列,将标记着该事务的提交,否则可以安全的 RollBack 该事务。
第二点,Percolator 的冲突检测是分布式的方案,针对 Write Set 中每个 Key 的冲突检测都至少需要各读写一次kv。对于目标是 OLTP 的 KV 系统,这将带来额外的延迟以及写放大。
-
Commit: Percolator 首先向 TSO 获取提交时间戳 $t_c$,之后检查 Primary 的 lock 列中版本为 $t_s$ 的数据是否存在,如果不存在,表明该事务已经被其他事务 abort,那么直接返回失败。否则,直接在 Primary Write 列的 $t_c$ 版本中写入数据 $t_s$,也就是将该事务写入 Commit Table. 写入 Primary key 的 Write 列之后,即标志着该事务已经被成功提交。之后对于所有 Secondary key,可以异步并行地修改其 Write 列和 lock 列的数据。
- Transaction Reads: 针对 Read Set 中的每个 Key,Percolator 首先读取其 lock 列,查看是否存在版本号小于 $t_s$ 的数据,如果存在,表明当前有正在执行或者中断了的事务。此时,如果该 lock 的 TTL 超时,那么 Client 可以根据 lock 中的记录索引到 Primary 的 Write 列(等价于查询 Commit Table)来决定 RollBack 或者 Commit 先前的事务,否则 Client 需要 BackOff 等待其他事务执行完成或者 TTL 超时。
总结而言,Percolator 采用了加锁的分布式事务解决方案,其基于 BigTable 本身的冲突检测实现很简单。然而,如果 client 出现执行异常,或者系统中的某些事务因为各种原因执行缓慢,Percolator 将不得不在等待之后采用额外的逻辑来清除残留的 lock,以保证后续的事务不被阻塞,这一过程将为写事务带来额外的延迟。同时 Percolator 通过在每一行中增加 lock 列和 Write 列,对于 TableDB 类的系统,也会带来额外的写放大。
尽管 Percolator 算法本身是非常简单的,但从理论到实践上,还有很多值得一提需要权衡的优化细节,这部分以后再详细介绍。
Omid 实现
Omid LL 为 Yahoo 于 VLDB 2018 提出的分布式事务系统,其作为 Apache Phoenix 的事务解决方案,为低延迟的 OLTP 系统所设计,其相比于 Percolator 的主要区别如下:
- Omid LL 采用了乐观并发控制,其在 Commit 阶段才进行冲突检测;
- Omid LL 采用集中式的无锁的冲突检测方案,所有的写事务将由 TSO 来检测冲突,因此不会产生因 client 失败而残留的锁问题;
- Omid LL 使用专有的 Commit Table (与 Data Table 分开) 来存储事务提交信息,并且在 Data Table 中的每一行中缓存该版本对应的提交信息 (Percolator 通过在 Data Table 中增加 Write 列来达到相同的目的);
这几点区别决定了 Omid LL 相比于 Percolator 具有更好的事务延迟,但其引入的冲突检测单点可能会带来可用性问题(可以通过主备的 HA 策略进行避免)。
Omid 在 KV 中记录的数据如下图:
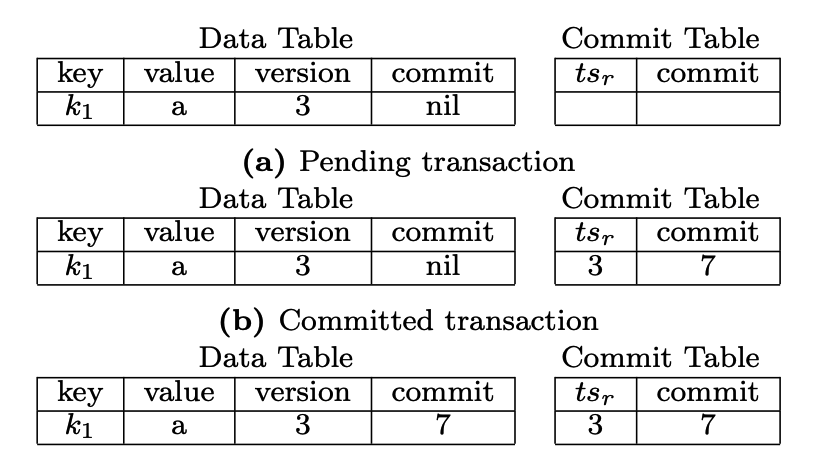
Commit Table 中记录了每个事务开始时间戳(事务版本)到提交时间戳的映射,一旦写入 Commit Table,则标志着当前事务提交完成。为了方便 Transaction Read 的版本检测,Omid 在 Data Table 中的每行也缓存了该版本对应的 commit 时间戳。事务在 Commit Table 中提交成功后,其提交时间戳可以异步的拷贝到 Data Table 中本次所写 WriteSet 的对应行中。
为了方便描述 Omid 的算法描述,其假设底层 KV 提供 check_and_mutate(key, field, old, new) 语义,该函数检查 key 对应的 field 的值,如果 field == old,那么替换成为 new;如果 old == null 并且 key 不存在,那么将 key 对应的 field 初始化成为 new;任何情况下该函数均返回 field 先前的值。
了解了相关背景,Omid 的实现方案具体如下:
- Begin: Begin 操作与 Percolator 类似,向中央节点 TSO 获取事务开始时间戳 $t_s$;
- Transaction Writes: Omid 采用乐观并发控制,其不在 Write 阶段检测冲突,因此写流程非常简单,client 只需将 Write Set 中的每个 key,带上当前事务的版本号 (key, $t_s$) 写入到 Data Table 中,注意该阶段写入的 key 的 commit 列置为 null;
-
Commit: client 通过向中心节点 TSO 发送 Commit 请求来获取提交时间戳病完成冲突检测。显然,请求中需要带上本次写事务的 WriteSet 以及 $t_s$ 给中心节点。
TSO 集中的仲裁事务冲突,考虑前面的章节中给出的集中式的冲突检测函数
CheckWWConflict。如果中心节点 TSO 使用该函数来检测冲突,则需要对每个写事务提交上来的 WriteSet 中的每个 key 都检测其 lastCommit 是否大于 $t_s$,这意味着 TSO 必须记录数据库中所有 key 的 lastCommit 信息,这显然是不可能的,因此必须采用其他方案来裁剪内存。裁剪的思路非常简单,就是在内存中维护一个 LRU 的数据结构记录已提交的 key 的 lastCommit 信息。TSO 在每次提交成功时,都会插入或更新当前事务 WriteSet 中每个 key 的 lastCommit 为当前的提交时间戳 $t_c$。如果在插入的过程中 LRU 满,那么淘汰 LRU 中 lastCommit 最小的那个 key。显然,这种方式会带来一个问题,如果事务提交上来的 WriteSet 中存在某几个 key 不在 LRU 中,TSO 就无法获取其 lastCommit 信息,也就无法检测冲突。
为了解决该问题,Omid 为 TSO 的 LRU 结构保持 \(LowWaterMark = Smallest(lastCommit)\text{ }in\text{ }LRU\) 根据上述 LRU 的淘汰策略可知,任何从 LRU 中淘汰的 key $x$ 均满足: \(lastCommit(x) < LowWaterMark\) 因此对于不在 LRU 中的 key 只需要判断 \(lastCommit(x) < LowWaterMark <= t_s\) 是否满足,如果成立,则判定该 key $x$ 未出现冲突,继续执行下一个 key 的检测即可。这种方案实现起来非常简单,但由于其并没有精确地保存每个 key 的 lastCommit,因此可能会带来一些错误的 abort 判断(不影响事务正确性)。考虑到每个 key 的 lastCommit 信息所需的内存往往仅需要20多字节,TSO 的内存中可以缓存大量 key 的 lastCommit 信息,因此错误的 abort 数会降到极低。
TSO 检测冲突成功之后会将提交时间戳 $t_c$ 返回给客户端,否则将返回 abort。Client 拿到 $t_c$ 之后向 Commit Table 发起
CT.check_and_mutate(ts, commit, null, tc)操作,试图在 Commit Table 中提交该事务,如果返回 ABORT,那么将中止事务,并且异步地清除先前写入到 Data Table 中的版本数据;如果 commit 成功,则异步地执行 Post-commit 流程,将写入 Commit Table 中的 $t_c$ 拷贝到 Data Table 中对应行的 commit 列中 (加速后续的 read 版本判断);完成所有 WriteSet 的异步拷贝成功之后执行垃圾回收,将该事务的提交信息从 Commit Table 中移除。至于这里为何需要check_and_mutate操作,与接下来要介绍的 Transaction Reads 有关。 -
Transaction Reads: 相对而言,Omid 的读过程流程会复杂一点,但其目标与所有支持 SI 的系统一致。针对每一个 key,按照从大到小的顺序,遍历所有小于 $t_s$ 的版本,返回第一个提交版本小于 $t_s$ 的 value 和对应的版本。
由上图可知,Omid 在 Data Table 的每一行也记录了当前版本对应的 $t_c$。对于 key $x$,在遍历的过程中,可以通过读取其 commit 列来判断 $x$ 当前的版本是否已提交并直接与 $t_s$ 进行比较。然而,如果读到 x.commit == null,则存在两种可能:
- 该版本对应的事务已经 Commit 成功,只是 Post-commit 还未成功执行;
- 该本本对应的事务未 Commit 成功;
为了区分上述两种情况,Omid 需要去 Commit Table 中查询当前读到的 $x$ 的版本 ver 是否有对应的提交记录;如果 CT 中未读到提交记录,则表明当前的事务还未提交成功,那么 client 将发起调用
CT.check_and_mutate(version, commit, null, ABORT)来将 ver 对应的事务设置为 ABORT。这样在 Commit 环节中,client 将在检测到 ABORT 后发起 abort 流程,清除残留数据。 如果标记 ABORT 成功,为了避免由于 Read 事务太慢而引起数据竞争,错误地将某个事务标记成为 ABORT,client 需要去 Data Store 中再次读取 x.ver 版本对应的 commit 列,如果读到 $t^{ver}_c$ 不为空并且 $t^{ver}_c < t_s$,那么返回对应的 value 和版本号,否则继续按照版本号从大到小遍历 $x$ 的下一个版本。Omid 为了降低延迟,将冲突检测交由单点的 TSO 来完成。从上述流程中可以看到,Omid 的冲突检测是全内存的比较操作,无需读写 KV,同时 TSO 本身除了需要持久化已分配的时间戳信息以外,无需持久化任何其他的信息(内存中的 LRU 无需进行持久化)。因此保持了 TSO 的无状态,方便从宕机中做 Recovery。相比于 Percolator,Omid 的 TSO 负载要更重,因此宕机的几率也更大。然而 Omid TSO 的宕机恢复是非常简单的,其只需要将 LowWaterMark 设置成为恢复时刻的时间戳,根据上述的冲突检测规则,恢复之后所有 $t_s$ < LowWaterMark 的的事务都会被报告冲突从而被 abort,不会影响任何事务的正确性。因此,Omid 可以通过一个简单的主备方案(依赖于 chubby)来实现事务系统的高可用。
总结
本文以分布式事务框架的角度总结了 Percolator 和 Omid 的设计思路。Percolator 和 Omid 分别采用了分布式和集中式的冲突检测方案,但其都需要一个集中式的 TSO 来获取时间戳。作为对比,后续有时间再介绍 CockroachDB 所使用的 Hybrid Logic Clock 的分布式时间戳获取方案。