leveldb 利用 cache 来通过一个 key 快速地检索到 value 值,其在 include/leveldb/cache.h 中定义了 cache 应该实现的接口。leveldb 要求 cache 实现内部的同步,从而可以让外部的线程并发地访问。像前面介绍的运行时环境 Env 一样,外部的使用者可以根据接口自定义其 cache 的实现。同时,leveldb 也提供了默认的基于 LRU(Least-Recently-Used) 的 cache。
我们首先看一下 cache 的定义,其在类定义的时候声明了一个 Rep 结构,并在类中定义了一个指向 Rep 的指针 rep_:
class Cache {
private:
struct Rep;
Rep* rep_;
...
}
在后面的学习中我们可以看到,在 table_builder 的定义中,作者也采用了这种方式。可能有很多人不明白作者为什么采用这种方式来定义类成员。事实上,这正是 Scott Meyers 在 Effective C++ 条款 31 所提到的
Minimize compilation dependencies between files (将文件间的编译依存关系降至最低)
而这种在类中包含一个指针成员,指向其具体实现的设计方式被称为 pimpl idiom。在这种方式下,cache 类本身能够完全与 Rep 类分离,任何对于 Rep 的未来修改都不需要重新编译使用到 cache 的文件,从而实现编译依存性的最小化。
言归正传,我们接下来直接看 leveldb 中 LRUCache 是如何实现的。LRUCache 的实现定义在文件 utils/cache.cc 中,我们可简单地把它理解成为 HashTable 和 LRU 链表的结合。每一个插入 cache 中的 Handle 都是用 key 作为哈希值插入到 HashTable 中,从而实现通过 key 快速检索 value 的目的。同时,HashTable 中的元素也按照 LRU 的原则串接在两个链表 lru_ 和 in_use_ 中,当 HashTable 空间不足时,会根据 LRU 的原则,从链表中选择最近未被使用过的 Handle 从表中删除。
首先来看包含了 (key,value) 对的 Handle 的实现:
struct LRUHandle {
void* value;
void (*deleter)(const Slice&, void* value);
LRUHandle* next_hash; // Hash 表指针,同样 Hash 值的 Handler 串接起来
LRUHandle* next; // LRU 双向链表指针
LRUHandle* prev; // LRU 双向链表指针
size_t charge; // 占用的空间
size_t key_length; // key 的长度
bool in_cache; // 该 Handle 是否在 cache 中
uint32_t refs; // 该 Handle 被引用到的次数,用于管理回收.
uint32_t hash; // Hash of key
char key_data[1]; // key 数据
}
注: GCC 由于对 C99 的支持,允许定义 char key_data[ ] 这样的柔性数组(Flexible Array)。但是由于 C++ 标准并不支持柔性数组的实现,这里定义为 key_data[1],这也是 c++ 中的标准做法。
每一个 LRUHandle 即是 HashTable 中的一个节点,相同 hash 值的节点通过字段 next_hash 串接,同时这些节点也通过字段 next 和 prev 串接成为双向链表。这里 leveldb 自己定义了一个简单的 HashTable,一方面免除了可移植方面的困扰,另一方面测试随机读也比 g++ 4.4.3 内置的 HashTable 快大约 5%.
HandleTable(也就是 Hash 表)使用一个 LRUHandler** list_ 来作为开散列表,并提供的操作:Insert,Remove 和 LookUp。由于实现比较简单,我们仅以 Insert 为例来简要说明一下:
LRUHandle* Insert(LRUHandle* h) {
LRUHandle** ptr = FindPointer(h->key(), h->hash);
LRUHandle* old = *ptr;
h->next_hash = (old == NULL ? NULL : old->next_hash);
// 如果存在相同的key,那么删除old
*ptr = h; // 与 *ptr->next_hash = h 的区别
if (old == NULL) {
++elems_;
if (elems_ > length_) {
Resize();
}
}
return old;
}
- 调用
FindPointer找到当前 key 和 hash 值所对应的那个LRUHandle的指针(如果没有,返回 slot 中的最后一个指针)。注意FindPointer返回的是LRUHandler**,也就是指针的指针,这里的作用类似于返回指针引用LRUHandler* &,也就是可以直接通过引用修改返回值的指向。 - 判断返回的
ptr是否是 NULL,如果是,表明表中没有当前的 key,那么直接插入到尾部,并调用Resize(),否则从 Hash 表中删除原来的指针ptr指向的节点,也就是用新节点替换旧节点。
Resize() 的作用是调整 Hash 表,使得每一个 slot 中的期望 Handle 的数量为1. 该函数首先将 LRUHandler** list_ 扩张成为 new_length,其中 new_length 是第一个大于 elem_ 的 2 的幂次,这主要是为了加速根据 hash 值选择 slot 的计算(因为 hash%new_length = hash & (new_length-1) )。
前面已经介绍过,HandleTable 中的节点还需要通过 LRU 链表管理起来,形成LRUCache。LRUCache 中的数据成员如下:
size_t capacity_; // lru 链表的容量
mutable port::Mutex mutex_; // 修改LRUCache时的并发保护
size_t usage_;
// Entries have refs==1 and in_cache==true.
LRUHandle lru_; // 双向循环链表,按照 LRU 原则组织
// Entries are in use by clients, and have refs >= 2 and in_cache==true.
LRUHandle in_use_; // 双向循环链表,当前正在被使用的节点
HandleTable table_; // hash 表
这里的同时定义了 lru_ 链表和 in_use_ 链表使得整个逻辑看起来有点绕。事实上,leveldb 根据引用数量来管理 table_ 中的 handle。如下图,我们可以把 LRUCache 内的 Handle 分为四个状态:
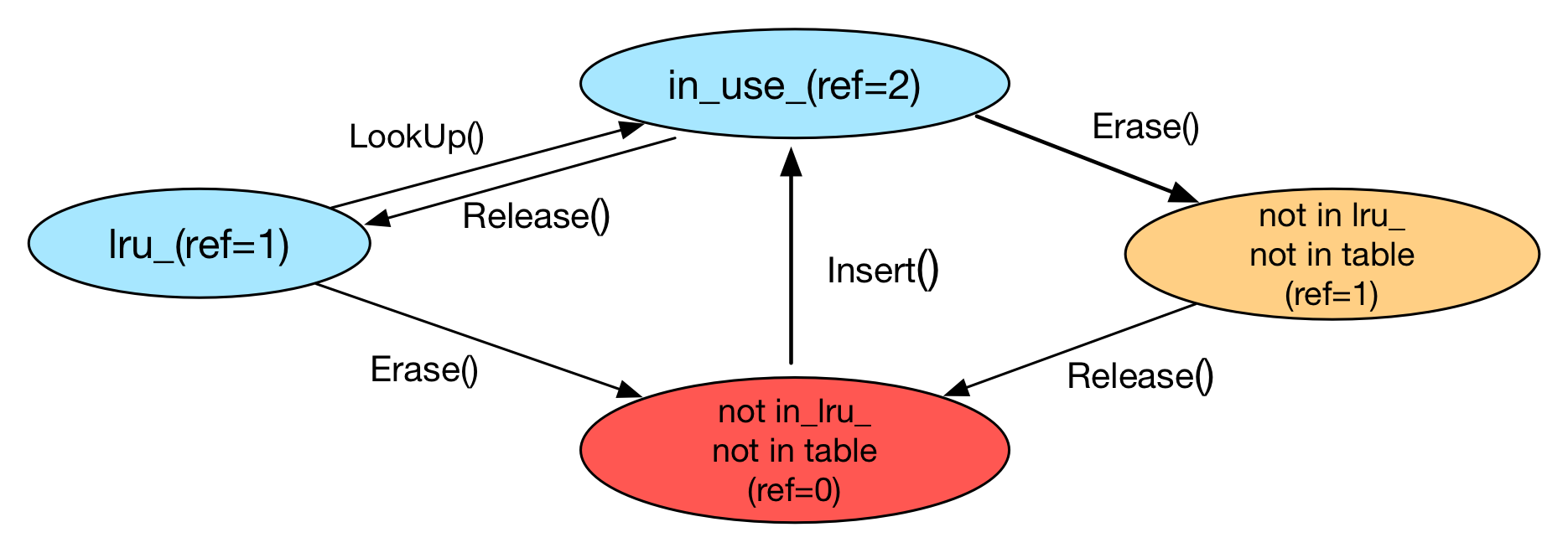
- in use (ref=2):该 Handle 在 HandleTable 中,并且串联在
in_use_链表中;由于该 Handle 既被外部使用,也被in_use_链表使用,因此有 ref=2; - in lru (ref=1):该 Handle 在 HandleTable 中,并且串联在
lru_链表中;由于该 Handle 只被lru_引用,因此 ref=1; - not in lru, not in table (ref=1):该 Handle 不在链表中也不再 HandleTable 中,但是仍然被外部引用而未释放,因此 ref=1;
- not in lru, not in table (ref=0):该 Handle 不在链表中也不再 HandleTable 中,也不被外部使用,因此 ref=0;
我们接下来对照上图看一下 LRUCache 提供给外部的接口。首先是 Insert 函数,这个函数首先创建一个新的 LRUHandle 并且设置相应的 key-value等数据;然后将该 Handle 串接到 in_use_ 链表头,并且将其 ref 设置成为 2(根据介绍想一下为什么),注意这里会从 Hash 表中删除原有的具有相同 key 值的 那个Handle。
if (capacity_ > 0) {
e->refs++; // for the cache's reference.
e->in_cache = true;
LRU_Append(&in_use_, e);
usage_ += charge;
FinishErase(table_.Insert(e)); //remove the same old key from cache
}
之后,该函数检测当前所有 cache 的条目所占的空间是否超过上限,如果超过上限,那么从 lru_ 链表中读取到最近未使用过的 Handle,并将其从 HashTable 和 lru_ 链表中删除来释放 LRUCache 的空间:
while (usage_ > capacity_ && lru_.next != &lru_) {
LRUHandle* old = lru_.next;
assert(old->refs == 1);
bool erased = FinishErase(table_.Remove(old->key(), old->hash));
if (!erased) { // to avoid unused variable when compiled NDEBUG
assert(erased);
}
}
LookUp 函数和 release 函数应该配对进行使用。LookUp 函数会从 HashTable 中返回当前 key 和 hash 值所对应的 Handle,并且将该 Handle 移动到 in_use_ 链表中。而 release 函数总是会将 Handle 从 in_use_ 链表中移除。LRUCache 还提供了 Erase 函数用来将一个 Handle 从 HashTable 中删除掉。需要注意的是,如果当前的 Handle 的引用数为 2,表明外部还有使用者在使用该 Handle,因此不能释放掉该 Handle 的内存,只能等待外部的使用者调用 release 之后才能将其释放掉。
最后我们在来看一下 leveldb 真实使用的封装好的 Cache 的类定义,也就是 ShardedLRUCache。 ShardedLRUCache 中定义了 16 个 LRUCache。每次进行插入或者查找时,首先使用 hash 值的最高 4 位来确定当前应该在哪个 LRUCache 中查找,然后在到对应的 LRUCache 中执行相关的操作。使用这种方式最重要的原因就是 LRUCache 的查找,插入和释放需要加锁,同时使用 16 个 LRUCache 能够提高对于 Cache 访问的并发,也就是从侧面降低了锁的粒度,提高访问效率。