每一个最初学习网络的人都会听到这样的一句话,TCP 是面向连接的基于字节流的传输协议,而UDP是基于数据包的无连接协议。这种把 TCP 比喻成为流的描述是非常形象的,因为我们知道 TCP 的滑动窗口协议能够保证数据源源不断的进入网络。可是问题是,如果我们仔细的观察每条 TCP 连接的表现,TCP 真的如我们想象的那样像水流一样顺滑的传输数据吗?
上面这个问题,如果仔细想一下应该就会回答不是。我们知道 TCP 也是一个数据包一个数据包进入网络,不同的数据包之间也是有发送间隔的,这种间隔就使得 TCP 在微观上看起来不是一个完整的流。不过,只能认识到这一点,并不能完全解答上面的问题。事实上,由于从收到包,网卡产生中断,拷贝数据到内核栈,内核向应用层递交数据是一个复杂的过程,TCP 的具体传输表现也会因此而受到种种影响。
TCP 中的 Train
早在 1986 年,Jain(如果你觉得 Jain 这个名字很熟,那就对了。这个人就是传说中的 Raj Jain,Jain’s Fairness Index 就是以他命名的,网络方面的大牛之一)以及 Routhier 就仔细地研究了MIT校园网络里面的 TCP 表现。他们发现TCP的数据流并没有呈现出流的形态,而是一个 burst 接着另一个 burst。这种传输形态使得 TCP 的数据包并没有在统计上满足一个泊松分布。他们为这种现象起了一个我觉得非常形象的名字:train(火车)。不得不说这个名字比现在的 flowlet,flowcell,flight,flier 的说法不知道好到哪里去了。
为什么叫火车呢?回到文章的最上面看下这张火车的图就明白了。事实上,每一个 TCP 的 burst(有一些数据包构成)就可以看做火车的一节车厢。如果两个报文之间的间隔低于一个阈值 $\alpha$,那么我们就认为这两个报文属于一节车厢;如果两节车厢之间的时间间隔超过了一个阈值 $\beta$,那么我们就认为这两节车厢属于不同的两个火车,很显然有 $\alpha < \beta$。
讲到这里你肯定在想,就算知道 TCP 这种火车的特性,对我们有什么用呢?我想说的是,这种特性非!常!有!用!事实上,这种 train 的性质是TCP传输在空间局部性和时间局部性的表现。这种局部性能够给网络中间件以及网络的端处理节省出很多计算或者存储开销。下文将会介绍一下内核协议栈中利用 train 特性的一种关键机制,很快你就会明白局部性总是会立功的。
网络报文的收发
在详细介绍具体的细节之前,需要花一点时间介绍一下“大部分人眼中”的报文收发流程。
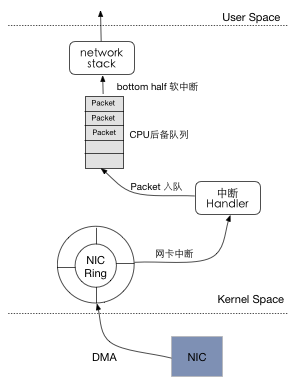
如上图所示,我们可以认为收发的流程经过了以下几个步骤:
- 网卡接收到数据包,通过 DMA 的方式将报文传送到内核的环形缓冲区。这块缓冲区由著名的内核数据结构
sk_buff所管理。 - 传送完成之后,网卡产生中断,通知 CPU 有数据包到来。此时由中断处理函数将报文(实际上是报文句柄)放入到响应中断的 CPU 的后备队列中。
- 报文开始进入内核网络栈处理。(需要注意的是,报文在网络栈中并不会被多次拷贝,这都要归功于
sk_buff)。 - 经过网络栈处理之后,报文中的负载部分会递交给用户空间的应用程序。
你觉得上面的过程非常自然对吗?是的,从逻辑上来说,这就是正常的Linux内核报文接收流程。不过如果你仔细想一下就会发现一个很大的问题:当今的局域网最大已经可以达到10Gbps的带宽,如果每个报文都对 CPU 产生一次中断,你让 CPU 怎么受得了?我们小小的计算一下在10Gbps的网络这能够每秒能够产生的中断数为: \(10Gbps * 1s \div 8 \div 1500B = 833333\) 这种规模的中断数 CPU 肯定是要呵呵了。如果 CPU 用尽全力响应会造成什么后果呢?那就是 CPU 占用率 100%,而吞吐率却只有 30% 左右。这告诉了我们一个很重要的道理,如果程序编写处理的不够好,再快的设备也发挥不出来作用,计算资源如此,网络资源也是如此。
中断缓和 (Interrupt Coalescing) 和 NAPI
中断缓和具体是干什么的呢?先来一段 wikipedia 对于中断缓和的解释:
Interrupt coalescing, also known as interrupt moderation, is a technique in which events which would normally trigger a hardware interrupt are held back, either until a certain amount of work is pending, or a timeout timer triggers
简而言之,就是把应该通过中断处理的事情累计起来,等到了某个时间通过一次中断全部执行。具体怎样将中断缓和应用到报文收发的流程中呢?那就是把多个数据包累积起来,然后通过一次中断处理这些数据包。在Linux内核中,NAPI 机制就是中断缓和技术的应用。
我们知道 CPU 对于外围设备的相应一般有两种:轮询和中断。轮询的方式在低负载的情况下实时性比较差,并且效率很低,而中断的方式在大负载下会大量消耗 CPU 资源。NAPI 正是基于以上观察而提出,其利用轮询的方式来减少中断的次数,从而缓和 CPU 在高带宽网络中的负载。图2简单的画了引入 NAPI 的网络栈收发流程,仔细看一下跟图1有什么不同呢?
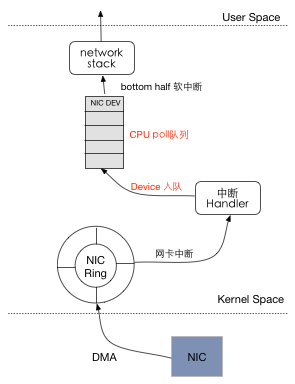
在开启了 NAPI 的内核中,网卡中断的处理函数会将当前的网卡设备加入到 CPU 的 poll_list 当中。这样,后面 CPU 通过调用网卡的 poll 函数,强制采用轮询的方式来读取后续报文。为了说的更清楚一点,我们还是列出在 NAPI 机制下的网络收包流程:
- 网卡接收到报文之后,同样是DMA到内核的环形缓冲区。
- 网卡产生一个中断,中断处理函数将该网卡挂入到 CPU 的轮询队列中,并且关掉硬中断,并触发软中断,即bottom half。
- CPU 在轮询队列中取出网络设备句柄,并且调用该设备的
poll函数,采用轮询的方式从网卡队列收包,此时不能响应新报文的中断。 - 当超过某个时限 $\delta$ 或者是接收完所有报文的时候,打开硬中断。
从上面的流程中可看到,当网卡接收到第一个包并产生中断以后,就会立即关闭中断响应,后续的数据包将不能够再向 CPU 发出中断请求,从而减少中断的次数。这时候我们回想一下在前文介绍的 burst 现象,你应该能够明白:哦,原来 burst 为中断缓和提供了一种天然的粒度。对于每一个 burst,只需要为它的第一个报文产生中断,然后对后续的报文使用轮询的机制就可以了。当一个 burst 中的所有报文都成功接收之后,再打开中断,接受下一个 burst 就可以了。
看到这儿,还有一个很大的问题没有解决:内核需要确定 burst 的长度,确定不同的 burst 之间的时间间隔,才能更加有效的利用 NAPI 的机制。这个问题就要交给所谓的 Adaptive-RX 和 Adaptive-TX 机制来实现了。简单来说,适应性传输和适应性接受,就是自动的确定最好的网络参数,例如自动地确定当前网络下每个 burst 的长度,不同 burst 之间的间隔等,从而提升网络的传输性能。
讲了这么多,也只是说了 TCP 这种 burst 特性到底可以干什么。那么 burst 到底是怎么产生的,又由哪些因素所影响呢?